4. Median of Two Sorted Arrays
There are two sorted arrays nums1 and nums2 of size m and n respectively.
Find the median of the two sorted arrays. The overall run time complexity should be O(log (m+n)).
You may assume nums1 and nums2 cannot be both empty.
Example 1:
nums1 = [1, 3]
nums2 = [2]
The median is 2.0
Example 2:
nums1 = [1, 2]
nums2 = [3, 4]
The median is (2 + 3)/2 = 2.5
这道题很有意思,虽然本科的时候就做过练习题,用二分查找递归的减少数据规模,但是当时只写过伪代码,这次真正写代码提交的时候,发现有很多BUG。
这个题的思路有3种:1)两个数组放一起排序,取中位数O((m+n)lg(m+n));2)用归并排序的方式把他们Merge到一块,取中间数O(m+n),其实边Merge边数数,Merge到(m+n)/2个数的时候就已经是中位数了;3)二分的思路,比较A,B数组的中位数,根据大小关系选择在前半段或后半段继续递归。
我开始尝试了二分的思路,很多测试样例不能通过,要考虑奇偶性等问题也导致代码不够优雅。查看网络发现可以把这一题转换为从两个已排序数组A,B中取第k小的元素的问题,如果是m+n是奇数,则取中间那个数,偶数则取中间两个数求平均。
关于从两个已排序数组A,B中取第k小的元素的问题,这篇文章有较详细的讨论。
下面简要讲一下最后一种O(lgm+lgn)的方法。
如果A的某个元素$A_i$和B的某两个连续元素$B_j$和$B_{j-1}$有关系$B_{j-1}\leq A_i\leq B_j$,那么可以确定$A_i$就是AB合起来的第$i+j+1$小的元素,因为$A_i$大于A中前$i$个元素,$A_i$又大于$B_{j-1}$,而$B_{j-1}$又大于B前面$j-1$个元素,所以在AB合起来的数组中,$A_i$大于A前面$i$个元素和B前面$j$个元素,排在第$i+j+1$的位置。同理如果$A_{i-1}\leq B_j\leq A_i$,则$B_j$是第$i+j+1$小的元素。
如果我们令$k=i+j+1$,则可以容易得到第$k$小的元素。关于i,j的取值问题,理论上i,j可以取任意值,只要满足$i+j=k-1$就可以了。不过常见的取法是先取$i$为A的中点,然后取$j=k-1-i$;或者按A,B元素个数的比例取值,比如上述链接中的代码。
上述链接中给出了如果A,B中不存在相同元素时的代码,如下:
int findKthSmallest(int A[], int m, int B[], int n, int k)
{
assert(m >= 0);
assert(n >= 0);
assert(k > 0);
assert(k <= m + n);
int i = (int)((double)m / (m + n) * (k – 1));
int j = (k – 1) – i;
assert(i >= 0);
assert(j >= 0);
assert(i <= m);
assert(j <= n); // invariant: i + j = k-1 // Note: A[-1] = -INF and A[m] = +INF to maintain invariant
int Ai_1 = ((i == 0) ? INT_MIN : A[i – 1]);
int Bj_1 = ((j == 0) ? INT_MIN : B[j – 1]);
int Ai = ((i == m) ? INT_MAX : A[i]);
int Bj = ((j == n) ? INT_MAX : B[j]);
if (Bj_1 < Ai && Ai < Bj)
return Ai;
else if (Ai_1 < Bj && Bj < Ai)
return Bj;
assert((Ai > Bj && Ai_1 > Bj) || (Ai < Bj && Ai < Bj_1)); // if none of the cases above, then it is either:
if (Ai < Bj) // exclude Ai and below portion // exclude Bj and above portion
return findKthSmallest(A + i + 1, m – i – 1, B, j, k – i – 1);
else /* Bj < Ai */ // exclude Ai and above portion // exclude Bj and below portion
return findKthSmallest(A, i, B + j + 1, n – j – 1, k – j – 1);
}
针对本题C++代码如下:
class Solution {
public:
double findKthSmallest(vector<int>& nums1, vector<int>& nums2, int k) //find kth smallest
{
int m = nums1.size(), n = nums2.size(); //always assume that m is equal or smaller than n
if (m > n)
return findKthSmallest(nums2, nums1, k);
if (m == 0)
return nums2[k – 1];
if (k == 1)
return min(nums1[0], nums2[0]); //divide k into two parts
int i = (int)((double)m / (m + n) * (k – 1));
int j = (k – 1) – i;
int Ai_1 = ((i == 0) ? INT_MIN : nums1[i – 1]);
int Bj_1 = ((j == 0) ? INT_MIN : nums2[j – 1]);
int Ai = ((i == m) ? INT_MAX : nums1[i]);
int Bj = ((j == n) ? INT_MAX : nums2[j]);
if (Bj_1 < Ai && Ai < Bj)
return Ai;
else if (Ai_1 < Bj && Bj < Ai)
return Bj;
if (Ai < Bj) {
vector<int> v1(nums1.begin() + i + 1, nums1.end());
vector<int> v2(nums2.begin(), nums2.begin() + j);
return findKthSmallest(v1, v2, k – i – 1);
}
else if (Ai > Bj) {
vector<int> v1(nums1.begin(), nums1.begin() + i);
vector<int> v2(nums2.begin() + j + 1, nums2.end());
return findKthSmallest(v1, v2, k – j – 1);
}
else
return Ai;
}
double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2)
{
int total = nums1.size() + nums2.size();
if (total & 0x01)
return findKthSmallest(nums1, nums2, total / 2 + 1);
else
return (findKthSmallest(nums1, nums2, total / 2) + findKthSmallest(nums1, nums2, total / 2 + 1)) / 2;
}
};
本代码提交AC,用时52MS。
二刷。
上面的解法真的太复杂了,完全记不住。从两个有序数组中求第K大的数,在http://www.geeksforgeeks.org/k-th-element-two-sorted-arrays/有非常详细的解法,归并O(m+n)的解法就不说了。
O(lgn+lgm)的解法。假设arr1和arr2的中位数分别是arr1[mid1]和arr2[mid2],如果mid1+mid2<k,说明两个中位数的位置都太小了,第k大的数比较大。如果arr1[mid1]<arr2[mid2],则mid1左边是这四块中最小的一块,k肯定不在这里,所以可以递归在[mid1+1,end1]和[start2,end2]之间找;arra1[mid1]>arr2[mid2]的情况类似。
如果mid1+mid2>k,说明第K大的数比较小,根据上面的分析,下次递归时,可以舍弃掉[start1,mid1], (mid1,end1], [start2,mid2], (mid2,end2]中较大的那块。比如arr1[mid1]>arr2[mid2],则可以舍弃掉(mid2,end2]。
这样每次都可以舍弃掉两个数组中的某个的一半,时间复杂度是O(lgm+lgn),代码在GeeksforGeeks中。
更优的O(lg(k))的方法是,每次我们不是取中值,而是取arr1[k/2]和arr2[k/2],直接根据这两个值的大小关系去分割递归。代码见GeeksforGeeks中最后一个版本的代码,简洁。
针对这一题,求两个有序数组的中位数,如果两个有序数组的总长度len是奇数,则中位数就是两个有序数组中的第len/2大数;如果len是偶数,则中位数是第len/2和len/2的平均数,所以最多需要两次调用findKth就可以得到结果。完整代码如下:
class Solution {
private:
int findKth(vector<int>& nums1, int s1, int e1, vector<int>& nums2, int s2, int e2, int k)
{
int len1 = e1 – s1 + 1, len2 = e2 – s2 + 1;
if (len1 > len2)
return findKth(nums2, s2, e2, nums1, s1, e1, k);
if (len1 == 0)
return nums2[s2 + k – 1];
if (k == 1)
return min(nums1[s1], nums2[s2]);
int i = s1 + min(k / 2, len1) – 1, j = s2 + min(k / 2, len2) – 1;
if (nums1[i] > nums2[j])
return findKth(nums1, s1, e1, nums2, j + 1, e2, k – (j – s2 + 1));
else
return findKth(nums1, i + 1, e1, nums2, s2, e2, k – (i – s1 + 1));
}
public:
double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2)
{
int m = nums1.size(), n = nums2.size();
if ((m + n) % 2) {
return findKth(nums1, 0, m – 1, nums2, 0, n – 1, (m + n) / 2 + 1);
}
else {
return (findKth(nums1, 0, m – 1, nums2, 0, n – 1, (m + n) / 2) + findKth(nums1, 0, m – 1, nums2, 0, n – 1, (m + n) / 2 + 1)) / 2.0;
}
}
};
本代码提交AC,用时65MS。
三刷。
这题有点难,还是看官方题解吧: https://leetcode.com/problems/median-of-two-sorted-arrays/solution/ 。
left_part | right_part
A[0], A[1], ..., A[i-1] | A[i], A[i+1], ..., A[m-1]
B[0], B[1], ..., B[j-1] | B[j], B[j+1], ..., B[n-1]
如上图所示。其实本质是我们要对数组A和B进行划分,使得left_part_A加left_part_B的元素个数等于right_part_A加right_part_B的元素个数。因为总元素个数是m+n,所以总的left_part的个数应该是(m+n)/2,当然为了统一处理奇偶问题,可以让left_part数目多一点为(m+n+1)/2。那么很自然的,如果A的划分点为i的话,为了满足总的left_part数目为(m+n+1)/2,则B的划分点就要为(m+n+1)/2-i。
也就是说,如果A的划分点为i,B的划分点为(m+n+1)/2-i时,我们就能保证left_part和right_part的数目相等。我们可以想象一下,i和j相当于两个隔板,当i向右移动时,left_part_A元素增加,为了维持平衡,则j一定要向左移动。那么问题就转换为这个i到底等于多少才能找到中位数。
中位数的含义是,所有左边的数都小于它,所有右边的数都大于它。因为A[i-1]<A[i]和B[j-1]<B[j]是天然成立的,为了找中位数,还需要保证A[i-1]<B[j]和B[j-1]<A[i]。所有,我们找i的过程就是在找满足A[i-1]<B[j]和B[j-1]<A[i]的i的过程。
那么,很自然的解法就是,假设i是A的中点,即二分m/2,求出对应的j的位置:(m+n+1)/2-i。然后看看A[i-1]<B[j]和B[j-1]<A[i]是否都满足,如果是的话,就找到了i和j,也就找到了中位数,中位数就是在i和j隔板附近的4个数中间。如果不满足A[i-1]<B[j],即A[i-1]>B[j],说明i的隔板太靠右了,导致A[i-1]太大了,所以要把i往左移一点。类似的,如果不满足B[j-1]<A[i],则把i往右移一点。
如果还不理解的话,可以看油管上的视频讲解: https://youtu.be/LPFhl65R7ww,下面的代码就是模仿这个视频写的。
class Solution {
public:
double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2) {
int m = nums1.size(), n = nums2.size();
if (m > n)return findMedianSortedArrays(nums2, nums1);
int low = 0, high = m;
while (low <= high) {
int partition1 = (low + high) / 2;
int partition2 = (m + n + 1) / 2 - partition1;
int maxleft1 = (partition1 == 0) ? INT_MIN : nums1[partition1 - 1];
int minright1 = (partition1 == m) ? INT_MAX : nums1[partition1];
int maxleft2 = (partition2 == 0) ? INT_MIN : nums2[partition2 - 1];
int minright2 = (partition2 == n) ? INT_MAX : nums2[partition2];
if (maxleft1 <= minright2 && maxleft2 <= minright1) {
if ((m + n) % 2 == 0) {
int mid1 = maxleft1 > maxleft2 ? maxleft1 : maxleft2;
int mid2 = minright1 < minright2 ? minright1 : minright2;
return (mid1 + mid2) / 2.0;
}
else {
return maxleft1 > maxleft2 ? maxleft1 : maxleft2;
}
}
else if (maxleft1 > minright2) {
high = partition1 - 1;
}
else if (maxleft2 > minright1) {
low = partition1 + 1;
}
}
return 0;
}
};
本代码提交AC,用时24MS。

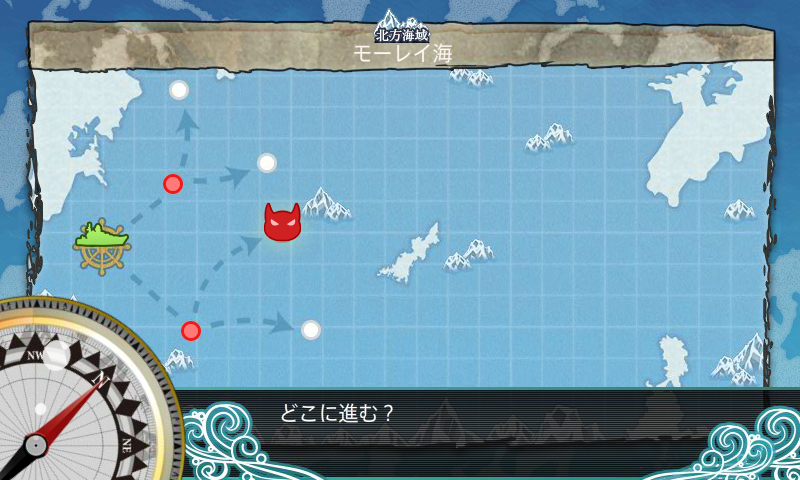 其中红色的点表示有敌人驻扎,猫头像的的点表示该地图敌军主力舰队(boss)的驻扎点,虚线表示各个战略点之间的航线(无向边)。
在游戏中要从一个战略点到相邻战略点需要满足一定的条件,即需要舰队的索敌值大于等于这两点之间航线的索敌值需求。
由于提高索敌值需要将攻击机、轰炸机换成侦察机,舰队索敌值越高,也就意味着舰队的战力越低。
另外在每一个战略点会发生一次战斗,需要消耗1/K的燃料和子弹。必须在燃料和子弹未用完的情况下进入boss点才能与boss进行战斗,所以舰队最多只能走过K条航路。
现在Nettle想要以最高的战力来进攻boss点,所以他希望能够找出一条从起始点(编号为1的点)到boss点的航路,使得舰队需要达到的索敌值最低,并且有剩余的燃料和子弹。
特别说明:两个战略点之间可能不止一条航线,两个相邻战略点之间可能不止一条航线。保证至少存在一条路径能在燃料子弹用完前到达boss点。
提示:你在找什么?
输入
第1行:4个整数N,M,K,T。N表示战略点数量,M表示航线数量,K表示最多能经过的航路,T表示boss点编号, 1≤N,K≤10,000, N≤M≤100,000
第2..M+1行:3个整数u,v,w,表示战略点u,v之间存在航路,w表示该航路需求的索敌值,1≤w≤1,000,000。
输出
第1行:一个整数,表示舰队需要的最小索敌值。
样例输入
5 6 2 5
1 2 3
1 3 2
1 4 4
2 5 2
3 5 5
4 5 3
样例输出
3
其中红色的点表示有敌人驻扎,猫头像的的点表示该地图敌军主力舰队(boss)的驻扎点,虚线表示各个战略点之间的航线(无向边)。
在游戏中要从一个战略点到相邻战略点需要满足一定的条件,即需要舰队的索敌值大于等于这两点之间航线的索敌值需求。
由于提高索敌值需要将攻击机、轰炸机换成侦察机,舰队索敌值越高,也就意味着舰队的战力越低。
另外在每一个战略点会发生一次战斗,需要消耗1/K的燃料和子弹。必须在燃料和子弹未用完的情况下进入boss点才能与boss进行战斗,所以舰队最多只能走过K条航路。
现在Nettle想要以最高的战力来进攻boss点,所以他希望能够找出一条从起始点(编号为1的点)到boss点的航路,使得舰队需要达到的索敌值最低,并且有剩余的燃料和子弹。
特别说明:两个战略点之间可能不止一条航线,两个相邻战略点之间可能不止一条航线。保证至少存在一条路径能在燃料子弹用完前到达boss点。
提示:你在找什么?
输入
第1行:4个整数N,M,K,T。N表示战略点数量,M表示航线数量,K表示最多能经过的航路,T表示boss点编号, 1≤N,K≤10,000, N≤M≤100,000
第2..M+1行:3个整数u,v,w,表示战略点u,v之间存在航路,w表示该航路需求的索敌值,1≤w≤1,000,000。
输出
第1行:一个整数,表示舰队需要的最小索敌值。
样例输入
5 6 2 5
1 2 3
1 3 2
1 4 4
2 5 2
3 5 5
4 5 3
样例输出
3