POJ 3070-Fibonacci
Fibonacci
| Time Limit: 1000MS | Memory Limit: 65536K | |
| Total Submissions: 26421 | Accepted: 17616 |
Description
In the Fibonacci integer sequence, F0 = 0, F1 = 1, and Fn = Fn − 1 + Fn − 2 for n ≥ 2. For example, the first ten terms of the Fibonacci sequence are:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, …
An alternative formula for the Fibonacci sequence is
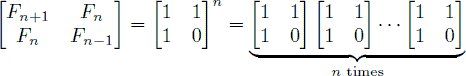
.
Given an integer n, your goal is to compute the last 4 digits of Fn.
Input
The input test file will contain multiple test cases. Each test case consists of a single line containing n (where 0 ≤ n ≤ 1,000,000,000). The end-of-file is denoted by a single line containing the number −1.
Output
For each test case, print the last four digits of Fn. If the last four digits of Fn are all zeros, print ‘0’; otherwise, omit any leading zeros (i.e., print Fn mod 10000).
Sample Input
0 9 999999999 1000000000 -1
Sample Output
0 34 626 6875
Hint
As a reminder, matrix multiplication is associative, and the product of two 2 × 2 matrices is given by
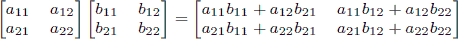
.
Also, note that raising any 2 × 2 matrix to the 0th power gives the identity matrix:
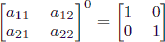
.
SourceStanford Local 2006
斐波那契数列是这样一个数列:0,1,1,2,3,5…,其数学定义为:
$$\begin{equation}f(n)=\begin{cases} 0, & n=0;\ 1, & n=1;\ f(n-1)+f(n-2), & n>1.\end{cases}\end{equation}$$
最简单的递归解法为:
typedef long long LL;
LL Fib1(int n)
{
if (n == 0)
return 0;
if (n == 1)
return 1;
return Fib1(n – 1) + Fib1(n – 2);
}这种算法的时间复杂度是 $O(2^n)$。 但是这种解法有很多重复计算,比如算f(8)=f(7)+f(6)时,f(7)重复计算了f(6)。所以我们可以从小开始算起,把f(n)的前两个值保存下来,每次滚动赋值,代码如下:
LL Fib2(int n)
{
if (n == 0)
return 0;
if (n == 1)
return 1;
LL fn_2 = 0, fn_1 = 1, ans = 0;
for (int i = 2; i <= n; ++i) {
ans = fn_1 + fn_2;
fn_2 = fn_1;
fn_1 = ans;
}
return ans;
}这种算法的时间复杂度是 $O(n)$。 最近遇到快速幂相关的题,发现求解斐波那契数列也可以用快速幂来求解,时间复杂度居然能降到 $O(lg(n))$。
题目的图中给出了斐波那契数列的矩阵形式,f(n)为矩阵[1,1;1,0]的n次幂的第一行第二个数。可以用归纳法证明。矩阵的n次幂和数的n次幂都可以用快速幂来求解,时间复杂度能降到 $O(lg(n))$。 代码如下:
const int MAXN = 2;
vector<vector<LL> > multi(const vector<vector<LL> >& mat1, const vector<vector<LL> >& mat2)
{
vector<vector<LL> > mat(MAXN, vector<LL>(MAXN, 0));
for (int i = 0; i < MAXN; ++i) {
for (int j = 0; j < MAXN; ++j) {
for (int k = 0; k < MAXN; ++k) {
mat[i][j] += mat1[i][k] * mat2[k][j];
}
}
}
return mat;
}
vector<vector<LL> > fastPow(vector<vector<LL> >& mat1, int n)
{
vector<vector<LL> > mat(MAXN, vector<LL>(MAXN, 0));
for (int i = 0; i < MAXN; ++i)
mat[i][i] = 1;
while (n != 0) {
if (n & 1)
mat = multi(mat, mat1);
mat1 = multi(mat1, mat1);
n >>= 1;
}
return mat;
}
LL Fib3(int n)
{
if (n == 0)
return 0;
if (n == 1)
return 1;
vector<vector<LL> > mat = { { 1, 1 }, { 1, 0 } };
vector<vector<LL> > matN = fastPow(mat, n);
return matN[0][1];
}POJ这题的代码如下,古老的POJ居然不支持第37行的vector初始化,崩溃。
#include <iostream> #include<cstdio>
#include <vector>
using namespace std;
typedef long long LL;
const int MAXN = 2;
const int MOD = 10000;
vector<vector<LL> > multi(const vector<vector<LL> >& mat1, const vector<vector<LL> >& mat2)
{
vector<vector<LL> > mat(MAXN, vector<LL>(MAXN, 0));
for (int i = 0; i < MAXN; ++i) {
for (int j = 0; j < MAXN; ++j) {
for (int k = 0; k < MAXN; ++k) {
mat[i][j] = (mat[i][j] + mat1[i][k] * mat2[k][j]) % MOD;
}
}
}
return mat;
}
vector<vector<LL> > fastPow(vector<vector<LL> >& mat1, int n)
{
vector<vector<LL> > mat(MAXN, vector<LL>(MAXN, 0));
for (int i = 0; i < MAXN; ++i)
mat[i][i] = 1;
while (n != 0) {
if (n & 1)
mat = multi(mat, mat1);
mat1 = multi(mat1, mat1);
n >>= 1;
}
return mat;
}
LL Fib3(int n)
{
if (n == 0)
return 0;
if (n == 1)
return 1;
//vector<vector<LL>> mat = { { 1,1 },{ 1,0 } }; //———————–
vector<vector<LL> > mat;
vector<LL> r1;
r1.push_back(1), r1.push_back(1);
vector<LL> r2;
r2.push_back(1), r2.push_back(0);
mat.push_back(r1);
mat.push_back(r2); //———————-
vector<vector<LL> > matN = fastPow(mat, n);
return matN[0][1];
}
int main()
{
int n;
while (scanf("%d", &n) && n != -1) {
LL ans = Fib3(n);
printf("%d\n", ans % MOD);
}
return 0;
}本代码提交AC,用时32MS,真的好快呀。