Given an Iterator class interface with methods: next() and hasNext(), design and implement a PeekingIterator that support the peek() operation — it essentially peek() at the element that will be returned by the next call to next().
Example:
Assume that the iterator is initialized to the beginning of the list: [1,2,3].
Call next() gets you 1, the first element in the list.
Now you call peek() and it returns 2, the next element. Calling next() after that still return 2.
You call next() the final time and it returns 3, the last element.
Calling hasNext() after that should return false.
Follow up: How would you extend your design to be generic and work with all types, not just integer?284. Peeking Iterator
class PeekingIterator : public Iterator {
private:
bool hasPeeked;
int peekedVal;
public:
PeekingIterator(const vector<int>& nums)
: Iterator(nums)
{
// Initialize any member here.
// **DO NOT** save a copy of nums and manipulate it directly. // You should only use the Iterator interface methods.
hasPeeked = false;
}
// Returns the next element in the iteration without advancing the iterator.
int peek()
{
if (hasPeeked)
return peekedVal;
peekedVal = Iterator::next();
hasPeeked = true;
return peekedVal;
}
//hasNext() and next() should behave the same as in the Iterator interface. // Override them if needed.
int next()
{
if (hasPeeked) {
hasPeeked = false;
return peekedVal;
}
return Iterator::next();
}
bool hasNext() const { return hasPeeked || Iterator::hasNext(); }
};
Serialization is the process of converting a data structure or object into a sequence of bits so that it can be stored in a file or memory buffer, or transmitted across a network connection link to be reconstructed later in the same or another computer environment.
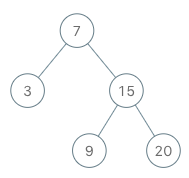
Design an algorithm to serialize and deserialize a binary tree. There is no restriction on how your serialization/deserialization algorithm should work. You just need to ensure that a binary tree can be serialized to a string and this string can be deserialized to the original tree structure.
Example:
You may serialize the following tree:
1
/ \
2 3
/ \
4 5
as "[1,2,3,null,null,4,5]"
Clarification: The above format is the same as how LeetCode serializes a binary tree. You do not necessarily need to follow this format, so please be creative and come up with different approaches yourself.
Note: Do not use class member/global/static variables to store states. Your serialize and deserialize algorithms should be stateless.
序列化一棵二叉树。要求把一棵二叉树转换为一个字符串,并且能根据这个字符串反序列化回原来的二叉树。 首先我们使用LeetCode Binary Tree Level Order Traversal层次遍历的方法得到二叉树的层次遍历序列,然后把数字转换为字符串并用逗号拼接起所有字符串,遇到空节点,则用空字符串表示。比如下面这棵树,序列化成字符串为:1,2,3,,,4,,,5。本来5后面还有空串的,即3的右孩子及其孩子,但是为了节省空间,后面的空串和逗号都省略了。
反序列化有点技巧。正常如果是一棵完全二叉树,如果下标从0开始,则节点i的左右孩子的下标分别为2*i+1和2*i+2,所以我们可以用递归的方法快速反序列化出来,就像我在LeetCode Minimum Depth of Binary Tree给出的根据数组构建树结构的genTree函数一样。对应到上图,完全二叉树的数组表示应该是{1,2,3,-1,-1,4,-1,-1,-1,-1,-1,-1,5,-1,-1},只有把这个数组传入genTree函数才能生成像上图的二叉树。 因为经过层次遍历之后的数组是{1,2,3,-1,-1,4,-1,-1,5},也就是说2后面只保留了其直接的两个空节点,并没有保留其4个空的孙子节点。导致4号节点(下标为5)在找孩子节点时,使用2*i+1=11和2*i+2=12找左右孩子的下标时,数组越界,导致漏掉了右孩子5。 后来参考了LeetCode官方的二叉树反序列化作者的介绍,恍然大悟。因为数组是层次遍历的结果,所以兄弟节点的孩子节点是按先后顺序存储在数组中的,我们可以分别维护一个父亲节点par和孩子节点child,一开始par=0,child=1,表示数组的0号节点为父亲节点,1号节点为左孩子节点,然后我们把child接到par的左孩子,把child+1接到par的右孩子,par++,child+=2,当遇到child为空,也要把空节点接到par上面。当遇到par为空时,直接跳过就好,但是child不移动。这样就能避免父亲为空,孩子节点的下标对不上的问题。比如上例中,par指向数值3时,左child指向数值4,右child指向-1;当par指向后面的两个-1时,child不动;当par指向4时,左child指向下一个-1,右child指向5正确。 完整代码如下:
class Codec {
public:
string bfs(TreeNode* root)
{
if (root == NULL)
return "";
string tree = "";
queue<TreeNode*> q;
q.push(root);
while (!q.empty()) {
TreeNode* t = q.front();
q.pop();
if (t == NULL) {
tree += ",";
continue;
}
tree += to_string(t->val) + ",";
q.push(t->left);
q.push(t->right);
}
return tree;
}
// Encodes a tree to a single string.
string serialize(TreeNode* root)
{
string tree = bfs(root);
if (tree == "")
return "";
int end = tree.size() – 1;
while (tree[end] == ‘,’)
–end;
return tree.substr(0, end + 1);
}
// Decodes your encoded data to tree.
TreeNode* deserialize(string data)
{
if (data == "")
return NULL;
vector<TreeNode*> tree;
for (int start = 0, end = 0; end <= data.size(); ++end) {
if (data[end] == ‘,’ || end == data.size()) {
string tmp = data.substr(start, end – start);
if (tmp == "")
tree.push_back(NULL);
else
tree.push_back(new TreeNode(atoi(tmp.c_str())));
start = end + 1;
}
}
int par = 0, child = 1;
while (child < tree.size()) {
if (tree[par]) {
if (child < tree.size())
tree[par]->left = tree[child++];
if (child < tree.size())
tree[par]->right = tree[child++];
}
++par;
}
return tree[0];
}
};
本代码提交AC,用时39MS。
二刷。逻辑性更好的代码:
class Codec {
public:
// Encodes a tree to a single string.
string serialize(TreeNode* root) {
vector<string> nodes;
queue<TreeNode*> q;
q.push(root);
while (!q.empty()) {
int n = q.size();
while (n--) {
TreeNode* cur = q.front();
q.pop();
if (cur == NULL)nodes.push_back("null");
else {
nodes.push_back(to_string(cur->val));
q.push(cur->left);
q.push(cur->right);
}
}
}
string ans = "";
int n = nodes.size();
for (int i = 0; i < n - 1; ++i) {
ans += nodes[i] + ",";
}
return ans + nodes[n - 1];
}
// Decodes your encoded data to tree.
TreeNode* deserialize(string data) {
vector<string> nodes;
int n = data.size();
int i = 0, j = 0;
while (i < n) {
j = i + 1;
while (j < n&&data[j] != ',')++j;
string cur = data.substr(i, j - i);
nodes.push_back(cur);
i = j + 1;
}
vector<TreeNode*> tnodes;
for (int i = 0; i < nodes.size(); ++i) {
if (nodes[i] == "null")tnodes.push_back(NULL);
else tnodes.push_back(new TreeNode(atoi(nodes[i].c_str())));
}
int par = 0, child = 1;
while (child < tnodes.size()) {
if (tnodes[par] == NULL) {
++par;
}
else {
tnodes[par]->left = tnodes[child++];
tnodes[par++]->right = tnodes[child++];
}
}
return tnodes[0];
}
};
LeetCode Insert Delete GetRandom O(1) – Duplicates allowed
Design a data structure that supports all following operations in averageO(1) time.
Note: Duplicate elements are allowed.
insert(val): Inserts an item val to the collection.
remove(val): Removes an item val from the collection if present.
getRandom: Returns a random element from current collection of elements. The probability of each element being returned is linearly related to the number of same value the collection contains.
Example:
// Init an empty collection.
RandomizedCollection collection = new RandomizedCollection();
// Inserts 1 to the collection. Returns true as the collection did not contain 1.
collection.insert(1);
// Inserts another 1 to the collection. Returns false as the collection contained 1. Collection now contains [1,1].
collection.insert(1);
// Inserts 2 to the collection, returns true. Collection now contains [1,1,2].
collection.insert(2);
// getRandom should return 1 with the probability 2/3, and returns 2 with the probability 1/3.
collection.getRandom();
// Removes 1 from the collection, returns true. Collection now contains [1,2].
collection.remove(1);
// getRandom should return 1 and 2 both equally likely.
collection.getRandom();
这一题在LeetCode Insert Delete GetRandom O(1)的基础上,增加了有重复元素的约束。还是用数组+Hash实现,但是Hash表中不再只是存储单个元素的下标了,而是存储所有相同元素的下标的集合,采用最大堆(priority_queue)来存储相同元素的下标集合。
插入时,数值插入到数组末尾,下标插入到hash表中该数值对应的最大堆中,如果堆原来为空的话,说明这是第一次插入该数值。删除时,取出val在数组中的最大下标(priority_queue.top()即为堆中最大值),如果不是数组末尾,则和数组末尾的数值交换,同时更新原数组末尾数值的下标最大堆,最后删掉数组末尾的数。产生随机数同样好办,直接rand下标。
完整代码如下:
[cpp]
class RandomizedCollection {
private:
unordered_map<int, priority_queue<int>> hash;
vector<int> nums;
public:
/** Initialize your data structure here. */
RandomizedCollection() {
}
/** Inserts a value to the collection. Returns true if the collection did not already contain the specified element. */
bool insert(int val) {
hash[val].push(nums.size());
nums.push_back(val);
return hash[val].size() == 1;
}
/** Removes a value from the collection. Returns true if the collection contained the specified element. */
bool remove(int val) {
if (hash[val].empty())return false;
int pos = hash[val].top();
hash[val].pop();
if (pos != nums.size() – 1) {
nums[pos] = nums[nums.size() – 1];
hash[nums[pos]].pop();
hash[nums[pos]].push(pos);
}
nums.pop_back();
return true;
}
/** Get a random element from the collection. */
int getRandom() {
return nums[rand() % nums.size()];
}
};
[/cpp]
本代码提交AC,用时85MS。
但是为什么要用最大堆来存储相同数值的下标集合呢,而且最大堆的插入和删除效率不是O(1)的呀,难道是因为相同的数比较少?所以每个数值的下标堆很小,所以插入和删除的复杂度近似为O(1)?
那么能否用数组来存储相同数值的下标集合呢,即用unordered_map<int, vector> hash,答案是不可以。举例如下:
假设经过了6次插入之后,数组为[10,10,20,20,30,30],此时不同数值的下标集合为:
即30的下标集合出现了错误,因为存储下标集合的数据结构是vector,O(1)的删除只能是pop_back(),但是这样并不能保证删掉最大的下标,本来这次我们是要删掉最大的下标4的,但是结果却删了0,依然保存了已不存在的下标4。所以用最大堆的目的就是为了每次删除都删掉最大的下标。
但是最大堆的插入和删除毕竟不是O(1),再次使用Hash存储下标才是真正的O(1)做法,即用unordered_map> hash,这样的话,在上面的例子中,我可以用O(1)的时间删除下标4。
[cpp]
class RandomizedCollection {
private:
unordered_map<int, unordered_set<int>> hash;
vector<int> nums;
public:
/** Initialize your data structure here. */
RandomizedCollection() {
}
/** Inserts a value to the collection. Returns true if the collection did not already contain the specified element. */
bool insert(int val) {
hash[val].insert(nums.size());
nums.push_back(val);
return hash[val].size() == 1;
}
/** Removes a value from the collection. Returns true if the collection contained the specified element. */
bool remove(int val) {
if (hash[val].empty())return false;
int pos = *hash[val].begin();
hash[val].erase(pos);
if (pos != nums.size() – 1) {
nums[pos] = nums[nums.size() – 1];
hash[nums[pos]].erase(nums.size() – 1);
hash[nums[pos]].insert(pos);
}
nums.pop_back();
return true;
}
/** Get a random element from the collection. */
int getRandom() {
return nums[rand() % nums.size()];
}
};
[/cpp]
本代码提交AC,用时79MS。]]>
LeetCode Insert Delete GetRandom O(1)
Design a data structure that supports all following operations in averageO(1) time.
insert(val): Inserts an item val to the set if not already present.
remove(val): Removes an item val from the set if present.
getRandom: Returns a random element from current set of elements. Each element must have the same probability of being returned.
Example:
// Init an empty set.
RandomizedSet randomSet = new RandomizedSet();
// Inserts 1 to the set. Returns true as 1 was inserted successfully.
randomSet.insert(1);
// Returns false as 2 does not exist in the set.
randomSet.remove(2);
// Inserts 2 to the set, returns true. Set now contains [1,2].
randomSet.insert(2);
// getRandom should return either 1 or 2 randomly.
randomSet.getRandom();
// Removes 1 from the set, returns true. Set now contains [2].
randomSet.remove(1);
// 2 was already in the set, so return false.
randomSet.insert(2);
// Since 2 is the only number in the set, getRandom always return 2.
randomSet.getRandom();
本题要求实现这样一种数据结构,插入、删除和产生集合中的一个随机数的时间复杂度都是O(1)。
插入和删除要是O(1),可以借助Hash,但Hash表不能以O(1)时间生成随机数。如果把数存在数组中,则能以O(1)的时间生成随机数,但数组的删除不能O(1)。所以可以把Hash和数组结合起来。
数字存储在数组中,Hash表中存储数字在数组中的下标。插入时,插入到数组末尾,同时更新Hash表中的下标。删除时,把数字和数组末尾的数字交换,这样删除数组末尾元素可以用O(1)时间完成,同时也要把Hash表中的下标抹掉,并更新原数组最后一个元素的下标。产生随机数就好办了,知道数组长度,rand下标就好。
完整代码如下:
[cpp]
class RandomizedSet {
private:
vector<int> nums;
unordered_map<int, int> hash;
public:
/** Initialize your data structure here. */
RandomizedSet() {
}
/** Inserts a value to the set. Returns true if the set did not already contain the specified element. */
bool insert(int val) {
if (hash.find(val) != hash.end())return false;
hash[val] = nums.size();
nums.push_back(val);
return true;
}
/** Removes a value from the set. Returns true if the set contained the specified element. */
bool remove(int val) {
if (hash.find(val) == hash.end())return false;
int pos = hash[val];
swap(nums[pos], nums[nums.size() – 1]);
//下面两句顺序不能乱,因为有可能删除的就是最后一个元素
hash[nums[pos]] = pos;
hash.erase(val);
nums.pop_back();
return true;
}
/** Get a random element from the set. */
int getRandom() {
return nums[rand() % nums.size()];
}
};
[/cpp]
本代码提交AC,用时59MS。]]>