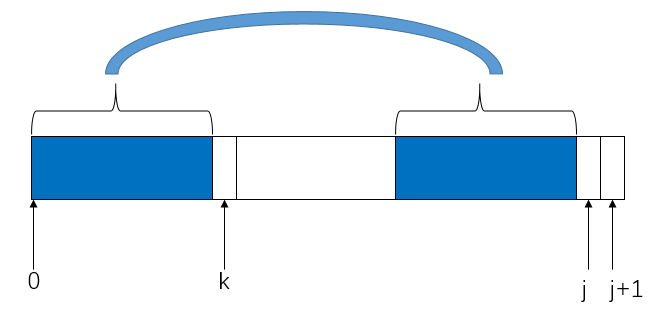
A string is called a happy prefix if is a non-empty prefix which is also a suffix (excluding itself).
Given a string s. Return the longest happy prefix of s .
Return an empty string if no such prefix exists.
Example 1:
Input: s = "level"
Output: "l"
Explanation: s contains 4 prefix excluding itself ("l", "le", "lev", "leve"), and suffix ("l", "el", "vel", "evel"). The largest prefix which is also suffix is given by "l".
Example 2:
Input: s = "ababab"
Output: "abab"
Explanation: "abab" is the largest prefix which is also suffix. They can overlap in the original string.
LeetCode Add Bold Tag in String
Given a string s and a list of strings dict, you need to add a closed pair of bold tag <b> and </b> to wrap the substrings in s that exist in dict. If two such substrings overlap, you need to wrap them together by only one pair of closed bold tag. Also, if two substrings wrapped by bold tags are consecutive, you need to combine them.
Example 1:
Input:
s = "abcxyz123"
dict = ["abc","123"]
Output:
"<b>abc</b>xyz<b>123</b>"
Example 2:
Input:
s = "aaabbcc"
dict = ["aaa","aab","bc"]
Output:
"<b>aaabbc</b>c"
Note:
The given dict won’t contain duplicates, and its length won’t exceed 100.
All the strings in input have length in range [1, 1000].
给定一个字符串s和一个字典dict,如果dict中的单词是s的子串,则要对这个子串加<b></b>的标签。如果有多个重叠的子串都需要加标签,则这些标签需要合并。比如样例2中,子串aaa、aab和bc重叠了,则他们的标签合并,最终结果就是<b>aaabbc</b>c。
这一题其实比第三题要简单。
因为有多个子串可能重叠,为了方便,设置一个长度和s一样的数组flag,flag[i]=1表示第i位需要被标签包围,flag[i]=0表示不需要被标签包围。
把dict中的每个字符串,去s中找,判断是否是s的子串,如果是,则把子串对应的flag位置1。当dict中的所有字符串都查完了。最后遍历flag,把连续1对应的子串加上标签就好了。
这里字符串匹配查找我直接用stl的find,自己写kmp也是可以的。完整代码如下:
[cpp]
class Solution {
public:
string addBoldTag(string s, vector<string>& dict) {
int n = s.size();
string flag(n, ‘0’);
for (const auto& sub : dict) {
size_t pos = s.find(sub, 0);
while (pos != string::npos) {
fill(flag.begin() + pos, flag.begin() + pos + sub.size(), ‘1’);
pos = s.find(sub, pos + 1);
}
}
string ans = "";
int i = 0, j = 0;
while (flag[i] == ‘0’)++i;
ans += s.substr(0, i);
while (i < n) {
int j = i + 1;
while (j < n&&flag[j] == ‘1’)++j;
ans += "<b>" + s.substr(i, j – i) + "</b>";
if (j >= n)break;
i = j;
while (j < n&&flag[j] == ‘0’)++j;
ans += s.substr(i, j – i);
i = j;
}
return ans;
}
};
[/cpp]
本代码提交AC,用时22MS。]]>