Implement strStr().
Return the index of the first occurrence of needle in haystack, or -1 if needle is not part of haystack.
Example 1:
Input: haystack = "hello", needle = "ll" Output: 2
Example 2:
Input: haystack = "aaaaa", needle = "bba" Output: -1
Clarification:
What should we return when needle is an empty string? This is a great question to ask during an interview.
For the purpose of this problem, we will return 0 when needle is an empty string. This is consistent to C’s strstr() and Java’s indexOf().
串的模式匹配问题,首先献上暴力方法:
class Solution {
public:
int strStr(string haystack, string needle)
{
int n1 = haystack.size(), n2 = needle.size();
if (n2 > n1)
return -1;
for (int i = 0; i < n1 – n2 + 1; i++) {
bool found = true;
for (int j = 0; j < n2; j++) {
if (needle[j] != haystack[i + j]) {
found = false;
break;
}
}
if (found)
return i;
}
return -1;
}
};本代码提交AC了,用时6MS。
然后使用神器KMP算法,如下:
class Solution {
public:
void getNextVal(vector<int>& nextval, string t)
{
int n = t.size();
nextval.resize(n);
nextval[0] = -1;
int j = 0, k = -1;
while (j < n – 1) {
if (k == -1 || t[j] == t[k]) {
j++;
k++;
if (t[j] != t[k])
nextval[j] = k;
else
nextval[j] = nextval[k];
}
else
k = nextval[k];
}
}
int strStr(string haystack, string needle)
{
if (needle == "")
return 0;
int n1 = haystack.size(), n2 = needle.size();
if (n2 > n1)
return -1;
vector<int> nextval;
getNextVal(nextval, needle);
int i = 0, j = 0;
while (i < n1 && j < n2) {
if (j == -1 || haystack[i] == needle[j]) {
i++;
j++;
}
else
j = nextval[j];
}
if (j >= n2)
return i – n2;
else
return -1;
}
};本代码提交AC,用时4MS。
下面还是仔细回顾一下KMP算法,免得以后忘了不好学。
假设主串为s,模式串为t,暴力的方法是依次检查以s[i]开头能否和t匹配成功,如果匹配不成功,则从s的下一个位置s[i+1]开始重新匹配。
但是如果遇到下图的情况:

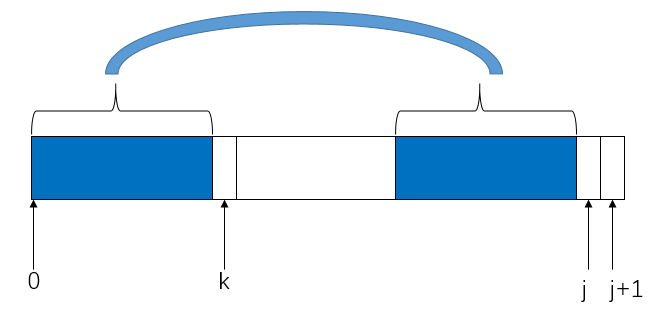
很显然,从s的下一个位置’B’开始和t的开头重新匹配时,一定会失败,因为之前匹配的串是”ABCDAB”,要想再次成功匹配,可以把AB的前缀移到AB后缀的地方,也就是指向主串的i指针不变,j指针指向’C’重新开始下一轮匹配。
那么怎样才能知道此时应该j指针应该调整到指向’C’呢?KMP算法的关键就是计算next数组了,next数组的作用就是当s[i]和t[j]失配时,i指针不动,j指针调整为next[j]继续匹配。


通过上面两张图的例子,我们知道next[j]的含义就是在t[j]之前的串中,相同的前缀和后缀的最大长度。比如最开始的图匹配到ABCDABD时失配,此时j指向最后一个字母’D’,’D’之前的串ABCDAB中最长的相同的前缀后缀是’AB’,所以next[j]=2,下一次,我们令j=next[j]=2,这样就直接从t[j]=t[2]=’C’开始匹配了。
(t[0,…,j]的前缀要以t[0]开头,后缀要以t[j]结尾,但都不能完全等于t[0,…,j],即前缀不能以t[j]结尾,后缀不能以t[0]开头。)
$$next[j]=\begin{cases} \max\{k|0<k<j|t_0t_1…t_{k-1}==t_{j-k}t_{j-k+1}…t_{j-1}\}, & \mbox{if this set is nonempty}\\-1, & \mbox{if }j==0\\ 0, & \mbox{otherwise}\end{cases}$$
既然next[j]的含义就是在t[j]之前的串中,相同的前缀和后缀的最大长度。假设我们已经知道next[0,…,j]了,怎样求解next[j+1]呢?假设next[j]=k,说明t[0,…,j-1]最长的相同前缀后缀长度为k。如果t[j]==t[k],则t[0,…,j]的最长的相同前缀后缀长度就是k+1了,即next[j+1]=k+1,这个很好理解。
如果t[j]!=t[k],则以t[j]结尾的长度为k的后缀就没戏了,因为t[0,…,k]!=t[j-k,…,j],但是后缀又必须以t[j]结尾,所以我们只能缩短长度,从next[k]处继续递归往前查找。即k=next[k]递归查找,注意,递归时j不变,只是k往前递归。
常规的next数组求解就是这样的,但是有一个地方还可以改进,下面引用july的博客:
比如图2和图3,如果用之前的next 数组方法求模式串“abab”的next 数组,可得其next 数组为-1 0 0 1(0 0 1 2整体右移一位,初值赋为-1),当它在图2的文本串去匹配的时候,发现b跟c失配,于是模式串右移j – next[j] = 3 – 1 =2位。
右移2位后,b又跟c失配(图3)。事实上,因为在上一步的匹配中,已经得知t[3] = b,与s[3] = c失配,而右移两位之后,让t[ next[3] ] = t[1] = b 再跟s[3]匹配时,必然失配。问题出在哪呢?
问题出在不该出现t[j] = t[ next[j] ]。为什么呢?理由是:当t[j] != s[i] 时,下次匹配必然是t[ next [j]] 跟s[i]匹配,如果t[j] = t[ next[j] ],必然导致后一步匹配失败(因为t[j]已经跟s[i]失配,然后你还用跟t[j]等同的值t[next[j]]去跟s[i]匹配,很显然,必然失配),所以不能允许t[j] = t[ next[j ]]。如果出现了t[j] = t[ next[j] ]咋办呢?如果出现了,则需要再次递归,即令next[j] = next[ next[j] ]。
所以,咱们得修改下求next 数组的代码。
//优化过后的next 数组求法
void GetNextval(char* p, int next[])
{
int pLen = strlen(p);
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen – 1) {
//p[k]表示前缀,p[j]表示后缀
if (k == -1 || p[j] == p[k]) {
++j;
++k;
//较之前next数组求法,改动在下面4行
if (p[j] != p[k])
next[j] = k; //之前只有这一行
else //因为不能出现p[j] = p[ next[j ]],所以当出现时需要继续递归,k = next[k] = next[next[k]]
next[j] = next[k];
}
else {
k = next[k];
}
}
}得到next数组就好办了,一旦t[j]!=s[i]失配,i不动,j=next[j]继续匹配。
二刷。上面的解读理解起来太费劲了,也记不住。在知乎上看到一个很好的解读:https://www.zhihu.com/question/21923021/answer/281346746
首先,KMP算法在主串和模式串的匹配阶段的原理很好理解,这个不用多讲。关键是如何求解模式串的next数组。
请看下图。核心思想是,要把求next数组的过程理解为模式串自己和自己匹配的过程,更具体来说,是模式串的后缀和前缀匹配的过程,因为next数组的含义就是后缀和前缀相等的最大长度。
如下图所示,首先令i和j错一个位置开始匹配,这就保证了j是从头开始匹配,匹配前缀;而i是从中间某个位置匹配,表示后缀。



下图就可以很直观的看出来j匹配的是前缀,i匹配的是后缀,只要i和j一直匹配,则j的长度就表示主串以i结尾时前缀和后缀相等的长度。所以,只要一直匹配,则next[i]=j。

如果匹配失败,则根据KMP的思路和next数组的定义,直接令j=next[j]进行跳转,i保持不动就行了,这就是KMP主串和模式串匹配的原理。

基于这个思想,其实求解next数组的过程和KMP匹配的过程很相似。完整代码如下:
class Solution {
public:
vector<int> GetNext(string s) {
int n = s.size();
vector<int> next(n, 0);
next[0] = -1;
int i = 0, j = -1;
while (i < n - 1) {
if (j == -1 || s[i] == s[j]) {
++i;
++j;
next[i] = j;
}
else {
j = next[j];
}
}
return next;
}
int strStr(string haystack, string needle) {
if (needle == "")return 0;
vector<int> next = GetNext(needle);
int m = haystack.size(), n = needle.size();
if (n > m)return -1;
int i = 0, j = 0;
while (i < m&&j < n) {
if (j == -1 || haystack[i] == needle[j]) {
++i;
++j;
}
else {
j = next[j];
}
}
if (j == n)return i - n;
else return -1;
}
};
Pingback: LeetCode Longest Happy Prefix | bitJoy > code