235. Lowest Common Ancestor of a Binary Search Tree
Given a binary search tree (BST), find the lowest common ancestor (LCA) of two given nodes in the BST.
According to the definition of LCA on Wikipedia: “The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow a node to be a descendant of itself).”
Given binary search tree: root = [6,2,8,0,4,7,9,null,null,3,5]
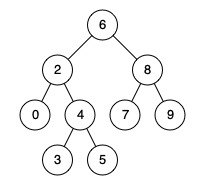
Example 1:
Input: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8 Output: 6 Explanation: The LCA of nodes2and8is6.
Example 2:
Input: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4 Output: 2 Explanation: The LCA of nodes2and4is2, since a node can be a descendant of itself according to the LCA definition.
Note:
- All of the nodes’ values will be unique.
- p and q are different and both values will exist in the BST.
给定一棵二叉搜索树和两个节点,问这两个节点的最近公共祖先(LCA)。LCA问题很久以前在hihoCoder上做过好多,用到一些比较高级的算法。 这个题的一个特点是二叉树是二叉搜索树,二叉搜索树的特点是左孩子小于等于根节点,根节点小于等于右孩子。不失一般性,令p<=q,所以如果p<=root<=q,则p,q分立root两边,则root就是p,q的LCA。如果p,q都小于root,则递归在root->left找。如果p,q都大于root,则递归在root->right找。 递归的算法很容易就实现了,代码如下:
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q)
{
if (p->val > q->val)
swap(p, q);
if (p->val <= root->val && q->val >= root->val)
return root;
if (p->val < root->val && q->val < root->val)
return lowestCommonAncestor(root->left, p, q);
if (p->val > root->val && q->val > root->val)
return lowestCommonAncestor(root->right, p, q);
}
};本代码提交AC,用时32MS。
二刷。遍历二叉树,把p和q的祖先找出来,然后寻找公共前缀:
class Solution {
void BSTSearch(TreeNode* root, TreeNode* p, vector<TreeNode*>& ancestors) {
while (root->val != p->val) {
ancestors.push_back(root);
if (p->val > root->val)root = root->right;
else root = root->left;
}
ancestors.push_back(root);
}
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
vector<TreeNode*> pa, qa;
BSTSearch(root, p, pa);
BSTSearch(root, q, qa);
int i = 0;
for (; i < pa.size() && i < qa.size(); ++i) {
if (pa[i] != qa[i])break;
}
return pa[i - 1];
}
};本代码提交AC,用时40MS。感觉还是第一种递归解法漂亮。