HDOJ 5418-Victor and World
Victor and World
Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 262144/131072 K (Java/Others)
Total Submission(s): 643 Accepted Submission(s): 268
Problem Description
After trying hard for many years, Victor has finally received a pilot license. To have a celebration, he intends to buy himself an airplane and fly around the world. There are n countries on the earth, which are numbered from 1 to n. They are connected by m undirected flights, detailedly the i-th flight connects the ui-th and the vi-th country, and it will cost Victor’s airplane wi L fuel if Victor flies through it. And it is possible for him to fly to every country from the first country.
Victor now is at the country whose number is 1, he wants to know the minimal amount of fuel for him to visit every country at least once and finally return to the first country.
Input
The first line of the input contains an integer T, denoting the number of test cases.
In every test case, there are two integers n and m in the first line, denoting the number of the countries and the number of the flights.
Then there are m lines, each line contains three integers ui, vi and wi, describing a flight.
1≤T≤20.
1≤n≤16.
1≤m≤100000.
1≤wi≤100.
1≤ui,vi≤n.
Output
Your program should print T lines : the i-th of these should contain a single integer, denoting the minimal amount of fuel for Victor to finish the travel.
Sample Input
1
3 2
1 2 2
1 3 3
Sample Output
10
Source
BestCoder Round #52 (div.2)
Recommend
hujie | We have carefully selected several similar problems for you: 5421 5420 5419 5416 5415
此题是可重复访问城市的旅行商问题(TSP),即从1号城市开始,经过每个城市至少一次,然后回到1号,问飞机消耗的最少燃料是多少。
根据题解,首先使用Floyd算法求出所有点对的最短路径dis[i][j],然后DP算法求解。
用一个整数s的二进制表示当前走过城市的状态,第i位为1表示第i个城市已经访问过,为0表示没访问过。dp[s][i]表示当前走过城市状态为s,且最后走过的城市编号为i,即到达了城市i。则有状态转移方程:
$$dp[s|(1<<i)][i]=min(dp[s][j]+dis[i][j])$$
条件为s&(1<<j)!=0且s&(1<<i)==0。
含义为:在s已经访问过j但是没有访问过i的情况下,转移到访问i的状态s|(1<<i)消耗的燃料为所有“s最后访问的是j消耗的燃料dp[s][j],加上从j走到i消耗的燃料之和”情况中的最小值。
最终结果就是s中所有位为1的状态,再从该状态回到城市1的燃料之和的最小值,即min(dp[(1<<n)-1][i]+dis[i][1])。
完整代码如下:
[cpp]
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int kMaxN = 17, kINF = 0x3f3f3f3f;
int dis[kMaxN][kMaxN], dp[1 << kMaxN][kMaxN];
int n, m;
void Init()
{
memset(dis, 0x3f, sizeof(dis));
memset(dp, 0x3f, sizeof(dp));
for (int i = 1; i <= n; i++)
dis[i][i] = 0;
}
void Floyd()
{
for (int k = 1; k <= n; k++)
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
dis[i][j] = min(dis[i][k] + dis[k][j], dis[i][j]);
}
int main()
{
freopen("input.txt", "r", stdin);
int t, u, v, w;
scanf("%d", &t);
while (t–)
{
scanf("%d %d", &n, &m);
Init();
while (m–)
{
scanf("%d %d %d", &u, &v, &w);
dis[u][v] = min(w, dis[u][v]);
dis[v][u] = dis[u][v];
}
Floyd();
dp[1][1] = 0;
for (int status = 1; status < (1 << n); status++)//枚举状态
{
for (int i = 1; i <= n; i++)//枚举最后访问的城市
{
//if (status&(1 << (i-1))==0)//(1)
if ((status&(1 << (i-1)))==0)//(2)i有没有访问过都可以
{
for (int j = 1; j <= n; j++)//枚举中间转折点
{
if (status&(1 << (j-1)))//(3)转折点j一定要访问过
dp[status | (1 << (i-1))][i] = min(dp[status | (1 << (i-1))][i], dp[status][j] + dis[i][j]);
}
}
}
}
int ans = kINF;
for (int i = 1; i <= n; i++)
ans = min(ans, dp[(1 << n) – 1][i] + dis[i][1]);
printf("%d\n", n == 1 ? 0 : ans);
}
return 0;
}
[/cpp]
本代码提交AC,用时717MS,内存10284K。
代码中需要注意一点,代码(2)一定不要写成了(1),要不然WA到死,&的优先级低于==,切记!
其实(2)处的if可以不要,因为本TSP问题可以重复访问某个城市,所以这里可以不判断下一步需要访问的城市之前有没有访问过,只是加了if能缩短时间;但是(3)处的if判断一定要,因为需要在城市j中转,j之前必须访问过。
另外查看大神的代码,发现很喜欢用0x3f3f3f3f而不是0x7fffffff作为程序中的无穷大,这是有道理的,详情看这篇博客。]]>
POJ 1094-Sorting It All Out
Sorting It All Out
Time Limit: 1000MS Memory Limit: 10000K
Total Submissions: 28397 Accepted: 9814
Description
An ascending sorted sequence of distinct values is one in which some form of a less-than operator is used to order the elements from smallest to largest. For example, the sorted sequence A, B, C, D implies that A < B, B < C and C < D. in this problem, we will give you a set of relations of the form A < B and ask you to determine whether a sorted order has been specified or not.
Input
Input consists of multiple problem instances. Each instance starts with a line containing two positive integers n and m. the first value indicated the number of objects to sort, where 2 <= n <= 26. The objects to be sorted will be the first n characters of the uppercase alphabet. The second value m indicates the number of relations of the form A < B which will be given in this problem instance. Next will be m lines, each containing one such relation consisting of three characters: an uppercase letter, the character “<” and a second uppercase letter. No letter will be outside the range of the first n letters of the alphabet. Values of n = m = 0 indicate end of input.
Output
For each problem instance, output consists of one line. This line should be one of the following three:
Sorted sequence determined after xxx relations: yyy…y.
Sorted sequence cannot be determined.
Inconsistency found after xxx relations.
where xxx is the number of relations processed at the time either a sorted sequence is determined or an inconsistency is found, whichever comes first, and yyy…y is the sorted, ascending sequence.
Sample Input
4 6
A<B
A<C
B<C
C<D
B<D
A<B
3 2
A<B
B<A
26 1
A<Z
0 0
Sample Output
Sorted sequence determined after 4 relations: ABCD.
Inconsistency found after 2 relations.
Sorted sequence cannot be determined.
Source
East Central North America 2001
POJ 2263-Heavy Cargo
Heavy Cargo
Time Limit: 1000MS Memory Limit: 65536K
Total Submissions: 3549 Accepted: 1894
Description
Big Johnsson Trucks Inc. is a company specialized in manufacturing big trucks. Their latest model, the Godzilla V12, is so big that the amount of cargo you can transport with it is never limited by the truck itself. It is only limited by the weight restrictions that apply for the roads along the path you want to drive.
Given start and destination city, your job is to determine the maximum load of the Godzilla V12 so that there still exists a path between the two specified cities.
Input
The input will contain one or more test cases. The first line of each test case will contain two integers: the number of cities n (2<=n<=200) and the number of road segments r (1<=r<=19900) making up the street network.
Then r lines will follow, each one describing one road segment by naming the two cities connected by the segment and giving the weight limit for trucks that use this segment. Names are not longer than 30 characters and do not contain white-space characters. Weight limits are integers in the range 0 – 10000. Roads can always be travelled in both directions.
The last line of the test case contains two city names: start and destination.
Input will be terminated by two values of 0 for n and r.
Output
For each test case, print three lines:
a line saying “Scenario #x” where x is the number of the test case
a line saying “y tons” where y is the maximum possible load
a blank line
Sample Input
4 3
Karlsruhe Stuttgart 100
Stuttgart Ulm 80
Ulm Muenchen 120
Karlsruhe Muenchen
5 5
Karlsruhe Stuttgart 100
Stuttgart Ulm 80
Ulm Muenchen 120
Karlsruhe Hamburg 220
Hamburg Muenchen 170
Muenchen Karlsruhe
0 0
Sample Output
Scenario #1
80 tons
Scenario #2
170 tons
Source
Ulm Local 1998
题意:给定一个公路核载图,图上标明了每一段公路载重限额,问从A地到B地最多能装载多少吨货物。这一题和POJ Problem 2240: Arbitrage有点相似,也是使用Floyd算法,稍作修改即可。
如上图所示,假设要从A到B,在用Floyd算法时,判断要不要借助C点,如果不借助,则load_ton[A][B]=80;如果借助C点,则路径变为A->C->B,A->C最多能载100吨,C->B最多能载90吨,所以总的来说,A->C->B最多能载min{100,90}=90吨;而90>80,所以借助C点后的载重大于不借助C点的载重,所以修改load_ton[A][B]=90。
知道这一点,我们可以很快的写出代码:
[cpp]
#include<iostream>
#include<map>
#include<string>
using namespace std;
const int MAX_N=202;
int load_ton[MAX_N][MAX_N];
//初始化数据
void init_load(int n)
{
for(int i=0;i<n;i++)
for(int j=0;j<n;j++)
load_ton[i][j]=0;
}
//改造Floyd算法
void Floyd(int n)
{
for(int k=0;k<n;k++)
{
for(int i=0;i<n;i++)
{
for(int j=0;j<n;j++)
{
int min_ton=load_ton[i][k]<load_ton[k][j]?load_ton[i][k]:load_ton[k][j];//这条路上的最小值即为能通过的最大值
if(load_ton[i][j]<min_ton)
{
load_ton[i][j]=min_ton;//对称矩阵
load_ton[j][i]=min_ton;//对称矩阵
}
}
}
}
}
int main()
{
//freopen("input.txt","r",stdin);
int n,r;
int case_num=1;
while(cin>>n>>r&&n&&r)
{
init_load(n);
map<string,int> city_index;//保存城市和下标的对应关系
string city1,city2;
int w;
int i=0;
while(r–)
{
cin>>city1>>city2>>w;
if(city_index.find(city1)==city_index.end())
city_index[city1]=i++;
if(city_index.find(city2)==city_index.end())
city_index[city2]=i++;
//load_ton[i-2][i-1]=w;//错,因为有可能cityi在之前已经加入了,这个时候i-1,i-2就不是cityi的下标了
//load_ton[i-1][i-2]=w;
load_ton[city_index[city1]][city_index[city2]]=w;//还是要从map里找对应下标
load_ton[city_index[city2]][city_index[city1]]=w;//因为路是两边通的,所以a[i][j]和a[j][i]相等
}
cin>>city1>>city2;
Floyd(n);
cout<<"Scenario #"<<case_num++<<endl;//
cout<<load_ton[city_index[city1]][city_index[city2]]<<" tons"<<endl<<endl;
}
return 0;
}
[/cpp]
本代码提交AC,用时79MS,内存316K。
在写代码的时候有几个小细节需要注意。在输入数据的时候,用MAP来保存城市和下标的关系,方便后面Floyd算法的操作;因为道路是双向通行的,所以保存数据时要保存成对称矩阵。
]]>
POJ 2240-Arbitrage
Arbitrage
Time Limit: 1000MS Memory Limit: 65536K
Total Submissions: 16195 Accepted: 6814
Description
Arbitrage is the use of discrepancies in currency exchange rates to transform one unit of a currency into more than one unit of the same currency. For example, suppose that 1 US Dollar buys 0.5 British pound, 1 British pound buys 10.0 French francs, and 1 French franc buys 0.21 US dollar. Then, by converting currencies, a clever trader can start with 1 US dollar and buy 0.5 * 10.0 * 0.21 = 1.05 US dollars, making a profit of 5 percent.
Your job is to write a program that takes a list of currency exchange rates as input and then determines whether arbitrage is possible or not.
Input
The input will contain one or more test cases. Om the first line of each test case there is an integer n (1<=n<=30), representing the number of different currencies. The next n lines each contain the name of one currency. Within a name no spaces will appear. The next line contains one integer m, representing the length of the table to follow. The last m lines each contain the name ci of a source currency, a real number rij which represents the exchange rate from ci to cj and a name cj of the destination currency. Exchanges which do not appear in the table are impossible.
Test cases are separated from each other by a blank line. Input is terminated by a value of zero (0) for n.
Output
For each test case, print one line telling whether arbitrage is possible or not in the format “Case case: Yes” respectively “Case case: No”.
Sample Input
3
USDollar
BritishPound
FrenchFranc
3
USDollar 0.5 BritishPound
BritishPound 10.0 FrenchFranc
FrenchFranc 0.21 USDollar
3
USDollar
BritishPound
FrenchFranc
6
USDollar 0.5 BritishPound
USDollar 4.9 FrenchFranc
BritishPound 10.0 FrenchFranc
BritishPound 1.99 USDollar
FrenchFranc 0.09 BritishPound
FrenchFranc 0.19 USDollar
Sample Output
Case 1: Yes
Case 2: No
Source
Ulm Local 1996
POJ 1125-Stockbroker Grapevine
Stockbroker Grapevine
Time Limit: 1000MS Memory Limit: 10000K
Total Submissions: 27559 Accepted: 15273
Description
Stockbrokers are known to overreact to rumours. You have been contracted to develop a method of spreading disinformation amongst the stockbrokers to give your employer the tactical edge in the stock market. For maximum effect, you have to spread the rumours in the fastest possible way.
Unfortunately for you, stockbrokers only trust information coming from their “Trusted sources” This means you have to take into account the structure of their contacts when starting a rumour. It takes a certain amount of time for a specific stockbroker to pass the rumour on to each of his colleagues. Your task will be to write a program that tells you which stockbroker to choose as your starting point for the rumour, as well as the time it will take for the rumour to spread throughout the stockbroker community. This duration is measured as the time needed for the last person to receive the information.
Input
Your program will input data for different sets of stockbrokers. Each set starts with a line with the number of stockbrokers. Following this is a line for each stockbroker which contains the number of people who they have contact with, who these people are, and the time taken for them to pass the message to each person. The format of each stockbroker line is as follows: The line starts with the number of contacts (n), followed by n pairs of integers, one pair for each contact. Each pair lists first a number referring to the contact (e.g. a ‘1’ means person number one in the set), followed by the time in minutes taken to pass a message to that person. There are no special punctuation symbols or spacing rules.
Each person is numbered 1 through to the number of stockbrokers. The time taken to pass the message on will be between 1 and 10 minutes (inclusive), and the number of contacts will range between 0 and one less than the number of stockbrokers. The number of stockbrokers will range from 1 to 100. The input is terminated by a set of stockbrokers containing 0 (zero) people.
Output
For each set of data, your program must output a single line containing the person who results in the fastest message transmission, and how long before the last person will receive any given message after you give it to this person, measured in integer minutes.
It is possible that your program will receive a network of connections that excludes some persons, i.e. some people may be unreachable. If your program detects such a broken network, simply output the message “disjoint”. Note that the time taken to pass the message from person A to person B is not necessarily the same as the time taken to pass it from B to A, if such transmission is possible at all.
Sample Input
3
2 2 4 3 5
2 1 2 3 6
2 1 2 2 2
5
3 4 4 2 8 5 3
1 5 8
4 1 6 4 10 2 7 5 2
2 2 5 1 5
Sample Output
3 2
3 10
Source
Southern African 2001
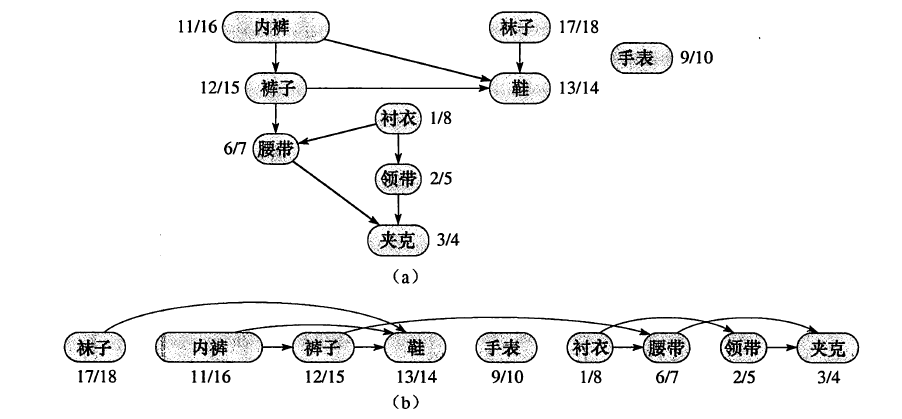 如上图是《算法导论》中关于拓扑排序的一个例子,这是某位教授起床后需要穿戴衣物的顺序,比如只有先穿了袜子才能穿鞋、但是穿鞋和戴手表并没有严格的先后顺序。拓扑排序的功能就是根据图(a)的拓扑图,得到图(b)中节点的先后顺序。
常见的拓扑排序算法有两种:Kahn算法和基于DFS的算法,这两种算法都很好理解,详细的解释请看维基百科
如上图是《算法导论》中关于拓扑排序的一个例子,这是某位教授起床后需要穿戴衣物的顺序,比如只有先穿了袜子才能穿鞋、但是穿鞋和戴手表并没有严格的先后顺序。拓扑排序的功能就是根据图(a)的拓扑图,得到图(b)中节点的先后顺序。
常见的拓扑排序算法有两种:Kahn算法和基于DFS的算法,这两种算法都很好理解,详细的解释请看维基百科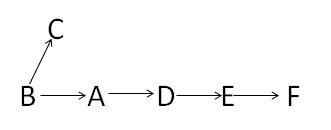 那么怎么判断生产的拓扑序列是否是严格的有序序列呢?基本原则就是就是任意取序列中的两个点,看能不能比较大小,如果能则是严格有序,否则不是。
我起初想到的是对拓扑序列的第一个节点进行深度遍历,遍历之后如果所有的节点都访问了,那么这是一个严格有序的序列,否则不是。后来证明这是不正确的,比如上图从B点开始DFS,遍历完F之后回溯到B点再访问C点,这样即使它不是严格有序的,但DFS还是访问了所有节点。
后来想到了Floyd算法。对拓扑图进行Floyd算法之后,会得到任意两点之间的最短距离。如果拓扑序列中前面的节点都可以到达后面的节点(最短距离不为无穷),则是严格有序的;否则不是。比如上图的一个拓扑序列为BCADEF(不唯一,还可以是BADEFC),但是C到ADEF的最短距离都是无穷,所以这个序列不是严格有序的。
把这些大的问题搞清楚之后就可以写代码了,一些小细节可以看我代码里的注释。
[cpp]
#include<iostream>
//#include<set>
#include<list>
#include<string>
#include<vector>
using namespace std;
int n,m;
const int MAX_N=26;
const int MAX_DIS=10000;
//*******这些都是维基百科关于拓扑排序(DFS版)里的变量含义
int temporary[MAX_N];
int permanent[MAX_N];
int marked[MAX_N];
//*******************************
int path[MAX_N][MAX_N];
//int dfs_visited[MAX_N];
list<int> L;//拓扑排序生产的顺序链
bool isDAG;//DAG=directed acyclic graph,无回路有向图
//每一个测试用例都要初始化路径
void init_path()
{
for(int i=0;i<n;i++)
for(int j=0;j<n;j++)
path[i][j]=0;
}
//每一次拓扑排序都要初始化temporary,permanent,marked
void init_tpm()
{
isDAG=true;
L.clear();
for(int i=0;i<n;i++)
{
temporary[i]=0;
permanent[i]=0;
marked[i]=0;
}
}
//递归访问。具体看维基百科
void visit(int i)
{
if(temporary[i]==1)
{
isDAG=false;
return;
}
else
{
if(marked[i]==0)
{
marked[i]=1;
temporary[i]=1;
for(int j=0;j<n;j++)
{
if(path[i][j]==1)
{
visit(j);
}
}
permanent[i]=1;
temporary[i]=0;
L.push_front(i);
}
}
}
/*
void init_dfs()
{
for(int i=0;i<n;i++)
dfs_visited[i]=0;
}*/
/*
//DFS有缺陷
void DFS(int v)
{
if(dfs_visited[v]==0)
{
dfs_visited[v]=1;
for(int i=0;i<n;i++)
{
if(dfs_visited[i]==0&&path[v][i]==1)
{
DFS(i);
}
}
}
}*/
//使用Floyd算法来判断生产的拓扑排序是否是严格有序的
bool Floyd()
{
int copy_path[MAX_N][MAX_N];
for(int i=0;i<n;i++)//首先复制一份路径图
for(int j=0;j<n;j++)
{
copy_path[i][j]=path[i][j];
if(i!=j&©_path[i][j]==0)//如果原来两点距离为0,说明他们是不直接连通的
copy_path[i][j]=MAX_DIS;//置为无穷
}
//floyd算法
for(int k=0;k<n;k++)
for(int i=0;i<n;i++)
for(int j=0;j<n;j++) if(copy_path[i][j]>copy_path[i][k]+copy_path[k][j])
copy_path[i][j]=copy_path[i][k]+copy_path[k][j];
vector<int> seq;//把原来用链表的拓扑序列转换成数组,方便后面的操作
list<int>::iterator it=L.begin();
while(it!=L.end())
{
seq.push_back(*it);
it++;
}
//如果这个拓扑链是严格有序的话,则前面的元素到后面的元素一定是可达的。
for(int i=0;i<n-1;i++)
{
for(int j=i+1;j<n;j++) { if(copy_path[seq[i]][seq[j]]>=MAX_DIS)//如果不可达,则不是严格有序的。
return false;
}
}
return true;
}
//拓扑排序DFS版本。返回0:有回路;1:虽然是拓扑排序,但非连通(不是严格有序);2:是拓扑排序且连通(严格有序)(即任意两个元素都可以比较大小)
int topological_sorting()
{
for(int i=0;i<n;i++)
{
if(marked[i]==0)
{
visit(i);
}
}
if(!isDAG)
return 0;
else
{
/*init_dfs();
DFS(*L.begin());
for(int i=0;i<n;i++) { if(dfs_visited[i]==0) { return 1; } }*/ if(Floyd()) return 2; else return 1; } } int main() { //freopen("input.txt","r",stdin); string tmp; while(cin>>n>>m&&n&&m)
{
init_path();
vector<string> relations(m);
int i;
for(i=0;i<m;i++)//一次性把所有输入都存起来,免得后续麻烦 { cin>>relations[i];
}
int rs=-1;
for(i=0;i<m;i++)//每增加一个关系,都要重新拓扑排序一次
{
init_tpm();//每次都要初始化
tmp=relations[i];
path[tmp[0]-‘A’][tmp[2]-‘A’]=1;
rs=topological_sorting();
if(rs==0)
{
cout<<"Inconsistency found after "<<i+1<<" relations."<<endl;
break;//如果是回路的话,后续的输入可以跳过
}
else if(rs==2)//成功
{
cout<<"Sorted sequence determined after "<<i+1<<" relations: ";
list<int>::iterator it=L.begin();
while(it!=L.end())
{
char c=’A’+*it;
cout<<c;
it++;
}
cout<<"."<<endl;
break;//后续输入跳过
}
}
if(i==m&&rs==1)//如果处理完所有输入都没有形成严格有序的拓扑序列
cout<<"Sorted sequence cannot be determined."<<endl;
}
return 0;
}
[/cpp]
我原本以为又是DFS,又是Floyd,算法时空效率会很低,但是提交后AC,用时125MS,内存244K,也不是很差。
代码中的拓扑排序算法使用的是基于DFS的版本,大家也可以改成Kahn算法。
如果觉得自己的代码是对的,但是提交WA的,可以使用这两个测试数据:
那么怎么判断生产的拓扑序列是否是严格的有序序列呢?基本原则就是就是任意取序列中的两个点,看能不能比较大小,如果能则是严格有序,否则不是。
我起初想到的是对拓扑序列的第一个节点进行深度遍历,遍历之后如果所有的节点都访问了,那么这是一个严格有序的序列,否则不是。后来证明这是不正确的,比如上图从B点开始DFS,遍历完F之后回溯到B点再访问C点,这样即使它不是严格有序的,但DFS还是访问了所有节点。
后来想到了Floyd算法。对拓扑图进行Floyd算法之后,会得到任意两点之间的最短距离。如果拓扑序列中前面的节点都可以到达后面的节点(最短距离不为无穷),则是严格有序的;否则不是。比如上图的一个拓扑序列为BCADEF(不唯一,还可以是BADEFC),但是C到ADEF的最短距离都是无穷,所以这个序列不是严格有序的。
把这些大的问题搞清楚之后就可以写代码了,一些小细节可以看我代码里的注释。
[cpp]
#include<iostream>
//#include<set>
#include<list>
#include<string>
#include<vector>
using namespace std;
int n,m;
const int MAX_N=26;
const int MAX_DIS=10000;
//*******这些都是维基百科关于拓扑排序(DFS版)里的变量含义
int temporary[MAX_N];
int permanent[MAX_N];
int marked[MAX_N];
//*******************************
int path[MAX_N][MAX_N];
//int dfs_visited[MAX_N];
list<int> L;//拓扑排序生产的顺序链
bool isDAG;//DAG=directed acyclic graph,无回路有向图
//每一个测试用例都要初始化路径
void init_path()
{
for(int i=0;i<n;i++)
for(int j=0;j<n;j++)
path[i][j]=0;
}
//每一次拓扑排序都要初始化temporary,permanent,marked
void init_tpm()
{
isDAG=true;
L.clear();
for(int i=0;i<n;i++)
{
temporary[i]=0;
permanent[i]=0;
marked[i]=0;
}
}
//递归访问。具体看维基百科
void visit(int i)
{
if(temporary[i]==1)
{
isDAG=false;
return;
}
else
{
if(marked[i]==0)
{
marked[i]=1;
temporary[i]=1;
for(int j=0;j<n;j++)
{
if(path[i][j]==1)
{
visit(j);
}
}
permanent[i]=1;
temporary[i]=0;
L.push_front(i);
}
}
}
/*
void init_dfs()
{
for(int i=0;i<n;i++)
dfs_visited[i]=0;
}*/
/*
//DFS有缺陷
void DFS(int v)
{
if(dfs_visited[v]==0)
{
dfs_visited[v]=1;
for(int i=0;i<n;i++)
{
if(dfs_visited[i]==0&&path[v][i]==1)
{
DFS(i);
}
}
}
}*/
//使用Floyd算法来判断生产的拓扑排序是否是严格有序的
bool Floyd()
{
int copy_path[MAX_N][MAX_N];
for(int i=0;i<n;i++)//首先复制一份路径图
for(int j=0;j<n;j++)
{
copy_path[i][j]=path[i][j];
if(i!=j&©_path[i][j]==0)//如果原来两点距离为0,说明他们是不直接连通的
copy_path[i][j]=MAX_DIS;//置为无穷
}
//floyd算法
for(int k=0;k<n;k++)
for(int i=0;i<n;i++)
for(int j=0;j<n;j++) if(copy_path[i][j]>copy_path[i][k]+copy_path[k][j])
copy_path[i][j]=copy_path[i][k]+copy_path[k][j];
vector<int> seq;//把原来用链表的拓扑序列转换成数组,方便后面的操作
list<int>::iterator it=L.begin();
while(it!=L.end())
{
seq.push_back(*it);
it++;
}
//如果这个拓扑链是严格有序的话,则前面的元素到后面的元素一定是可达的。
for(int i=0;i<n-1;i++)
{
for(int j=i+1;j<n;j++) { if(copy_path[seq[i]][seq[j]]>=MAX_DIS)//如果不可达,则不是严格有序的。
return false;
}
}
return true;
}
//拓扑排序DFS版本。返回0:有回路;1:虽然是拓扑排序,但非连通(不是严格有序);2:是拓扑排序且连通(严格有序)(即任意两个元素都可以比较大小)
int topological_sorting()
{
for(int i=0;i<n;i++)
{
if(marked[i]==0)
{
visit(i);
}
}
if(!isDAG)
return 0;
else
{
/*init_dfs();
DFS(*L.begin());
for(int i=0;i<n;i++) { if(dfs_visited[i]==0) { return 1; } }*/ if(Floyd()) return 2; else return 1; } } int main() { //freopen("input.txt","r",stdin); string tmp; while(cin>>n>>m&&n&&m)
{
init_path();
vector<string> relations(m);
int i;
for(i=0;i<m;i++)//一次性把所有输入都存起来,免得后续麻烦 { cin>>relations[i];
}
int rs=-1;
for(i=0;i<m;i++)//每增加一个关系,都要重新拓扑排序一次
{
init_tpm();//每次都要初始化
tmp=relations[i];
path[tmp[0]-‘A’][tmp[2]-‘A’]=1;
rs=topological_sorting();
if(rs==0)
{
cout<<"Inconsistency found after "<<i+1<<" relations."<<endl;
break;//如果是回路的话,后续的输入可以跳过
}
else if(rs==2)//成功
{
cout<<"Sorted sequence determined after "<<i+1<<" relations: ";
list<int>::iterator it=L.begin();
while(it!=L.end())
{
char c=’A’+*it;
cout<<c;
it++;
}
cout<<"."<<endl;
break;//后续输入跳过
}
}
if(i==m&&rs==1)//如果处理完所有输入都没有形成严格有序的拓扑序列
cout<<"Sorted sequence cannot be determined."<<endl;
}
return 0;
}
[/cpp]
我原本以为又是DFS,又是Floyd,算法时空效率会很低,但是提交后AC,用时125MS,内存244K,也不是很差。
代码中的拓扑排序算法使用的是基于DFS的版本,大家也可以改成Kahn算法。
如果觉得自己的代码是对的,但是提交WA的,可以使用这两个测试数据: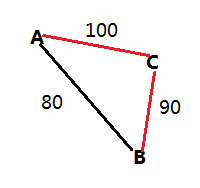 如上图所示,假设要从A到B,在用Floyd算法时,判断要不要借助C点,如果不借助,则load_ton[A][B]=80;如果借助C点,则路径变为A->C->B,A->C最多能载100吨,C->B最多能载90吨,所以总的来说,A->C->B最多能载min{100,90}=90吨;而90>80,所以借助C点后的载重大于不借助C点的载重,所以修改load_ton[A][B]=90。
知道这一点,我们可以很快的写出代码:
[cpp]
#include<iostream>
#include<map>
#include<string>
using namespace std;
const int MAX_N=202;
int load_ton[MAX_N][MAX_N];
//初始化数据
void init_load(int n)
{
for(int i=0;i<n;i++)
for(int j=0;j<n;j++)
load_ton[i][j]=0;
}
//改造Floyd算法
void Floyd(int n)
{
for(int k=0;k<n;k++)
{
for(int i=0;i<n;i++)
{
for(int j=0;j<n;j++)
{
int min_ton=load_ton[i][k]<load_ton[k][j]?load_ton[i][k]:load_ton[k][j];//这条路上的最小值即为能通过的最大值
if(load_ton[i][j]<min_ton)
{
load_ton[i][j]=min_ton;//对称矩阵
load_ton[j][i]=min_ton;//对称矩阵
}
}
}
}
}
int main()
{
//freopen("input.txt","r",stdin);
int n,r;
int case_num=1;
while(cin>>n>>r&&n&&r)
{
init_load(n);
map<string,int> city_index;//保存城市和下标的对应关系
string city1,city2;
int w;
int i=0;
while(r–)
{
cin>>city1>>city2>>w;
if(city_index.find(city1)==city_index.end())
city_index[city1]=i++;
if(city_index.find(city2)==city_index.end())
city_index[city2]=i++;
//load_ton[i-2][i-1]=w;//错,因为有可能cityi在之前已经加入了,这个时候i-1,i-2就不是cityi的下标了
//load_ton[i-1][i-2]=w;
load_ton[city_index[city1]][city_index[city2]]=w;//还是要从map里找对应下标
load_ton[city_index[city2]][city_index[city1]]=w;//因为路是两边通的,所以a[i][j]和a[j][i]相等
}
cin>>city1>>city2;
Floyd(n);
cout<<"Scenario #"<<case_num++<<endl;//
cout<<load_ton[city_index[city1]][city_index[city2]]<<" tons"<<endl<<endl;
}
return 0;
}
[/cpp]
本代码提交AC,用时79MS,内存316K。
在写代码的时候有几个小细节需要注意。在输入数据的时候,用MAP来保存城市和下标的关系,方便后面Floyd算法的操作;因为道路是双向通行的,所以保存数据时要保存成对称矩阵。
]]>
如上图所示,假设要从A到B,在用Floyd算法时,判断要不要借助C点,如果不借助,则load_ton[A][B]=80;如果借助C点,则路径变为A->C->B,A->C最多能载100吨,C->B最多能载90吨,所以总的来说,A->C->B最多能载min{100,90}=90吨;而90>80,所以借助C点后的载重大于不借助C点的载重,所以修改load_ton[A][B]=90。
知道这一点,我们可以很快的写出代码:
[cpp]
#include<iostream>
#include<map>
#include<string>
using namespace std;
const int MAX_N=202;
int load_ton[MAX_N][MAX_N];
//初始化数据
void init_load(int n)
{
for(int i=0;i<n;i++)
for(int j=0;j<n;j++)
load_ton[i][j]=0;
}
//改造Floyd算法
void Floyd(int n)
{
for(int k=0;k<n;k++)
{
for(int i=0;i<n;i++)
{
for(int j=0;j<n;j++)
{
int min_ton=load_ton[i][k]<load_ton[k][j]?load_ton[i][k]:load_ton[k][j];//这条路上的最小值即为能通过的最大值
if(load_ton[i][j]<min_ton)
{
load_ton[i][j]=min_ton;//对称矩阵
load_ton[j][i]=min_ton;//对称矩阵
}
}
}
}
}
int main()
{
//freopen("input.txt","r",stdin);
int n,r;
int case_num=1;
while(cin>>n>>r&&n&&r)
{
init_load(n);
map<string,int> city_index;//保存城市和下标的对应关系
string city1,city2;
int w;
int i=0;
while(r–)
{
cin>>city1>>city2>>w;
if(city_index.find(city1)==city_index.end())
city_index[city1]=i++;
if(city_index.find(city2)==city_index.end())
city_index[city2]=i++;
//load_ton[i-2][i-1]=w;//错,因为有可能cityi在之前已经加入了,这个时候i-1,i-2就不是cityi的下标了
//load_ton[i-1][i-2]=w;
load_ton[city_index[city1]][city_index[city2]]=w;//还是要从map里找对应下标
load_ton[city_index[city2]][city_index[city1]]=w;//因为路是两边通的,所以a[i][j]和a[j][i]相等
}
cin>>city1>>city2;
Floyd(n);
cout<<"Scenario #"<<case_num++<<endl;//
cout<<load_ton[city_index[city1]][city_index[city2]]<<" tons"<<endl<<endl;
}
return 0;
}
[/cpp]
本代码提交AC,用时79MS,内存316K。
在写代码的时候有几个小细节需要注意。在输入数据的时候,用MAP来保存城市和下标的关系,方便后面Floyd算法的操作;因为道路是双向通行的,所以保存数据时要保存成对称矩阵。
]]>
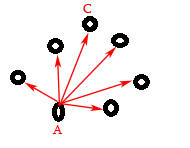
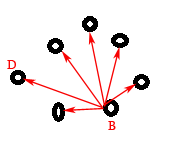 假设分别从A点和B点开始的单源最短距离如上两张图所示,那么Stockbroker从A点开始传播谣言总共需要多长时间呢?因为传播是可以同时进行的,所以传播结束时间就是A点到其他点中的最长距离,也就是上图中的AC。同理,如果从B点开始,则|BD|是传播时间。
综上所述,本题的求解过程可以归纳为以下几步:
1. 测试图中的每一个点$$i$$,求从该点出发,到其他所有点的单源最短距离集合$$S_i$$
2. 求出该单源最短距离$$S_i$$内部的最大值$$M_i$$
3. 对于图中的所有点,求其$$M_i$$
4. 最后求所有$$M_i$$中的最小值$$MIN$$,即为最终结果
所以根据上面的步骤,我们可以用n次Dijkstra算法求每个点的单源最短距离内部的最大值$$M_i$$,然后求$$MIN$$。其实也可以不用这么麻烦,因为我们还有另外一个更简单的算法Floyd算法。使用Floyd算法求得所有点对的最短距离,自然就知道某个点的单源最短距离了。
在写代码的时候还有一些小问题需要注意,对于数据输入,请仔细多读几遍Input说明,如果还是有困难,请看
假设分别从A点和B点开始的单源最短距离如上两张图所示,那么Stockbroker从A点开始传播谣言总共需要多长时间呢?因为传播是可以同时进行的,所以传播结束时间就是A点到其他点中的最长距离,也就是上图中的AC。同理,如果从B点开始,则|BD|是传播时间。
综上所述,本题的求解过程可以归纳为以下几步:
1. 测试图中的每一个点$$i$$,求从该点出发,到其他所有点的单源最短距离集合$$S_i$$
2. 求出该单源最短距离$$S_i$$内部的最大值$$M_i$$
3. 对于图中的所有点,求其$$M_i$$
4. 最后求所有$$M_i$$中的最小值$$MIN$$,即为最终结果
所以根据上面的步骤,我们可以用n次Dijkstra算法求每个点的单源最短距离内部的最大值$$M_i$$,然后求$$MIN$$。其实也可以不用这么麻烦,因为我们还有另外一个更简单的算法Floyd算法。使用Floyd算法求得所有点对的最短距离,自然就知道某个点的单源最短距离了。
在写代码的时候还有一些小问题需要注意,对于数据输入,请仔细多读几遍Input说明,如果还是有困难,请看