LeetCode Range Sum Query – Mutable Given an integer array nums, find the sum of the elements between indices i and j (i ≤ j), inclusive. The update(i, val) function modifies nums by updating the element at index i to val. Example:
Given nums = [1, 3, 5] sumRange(0, 2) -> 9 update(1, 2) sumRange(0, 2) -> 8Note:
- The array is only modifiable by the update function.
- You may assume the number of calls to update and sumRange function is distributed evenly.
给定一个一维数组,要求实现范围求和,即求[i,j]之间的元素的和。sumRange(i,j)求i~j的元素和,update(i,val)更新下标为i的元素值为val。 第一敏感使用线段树,很久之前在hihoCoder上遇到过。 建树的方法是类似于树的后序遍历,即左右根。不断把[start,end]二分,构建左右子树,然后构建当前节点,当前节点的sum等于左右子树的sum的和。在递归的时候,递归到start==end时,说明只有一个元素了,此时sum就等于该元素。 查询的方法和建树方法类似,判断区间[i,j]和区间[start,end]的关系,假设start和end的中点是mid,如果j<=mid,递归在左子树查询;如果i>mid,递归在右子树查询;否则在[i,mid]和[mid+1,j]查询然后求和。 更新的方法和查询的方法类似,也是不断判断i和mid的关系,在左子树或者右子树递归更新,当找到该叶子节点时,更新它的sum,返回父节点也更新sum等于新的左右子树的sum的和。 完整代码如下: [cpp] class NumArray { private: struct Node { int start, end, sum; Node *left, *right; Node(int s, int e) :start(s), end(e), sum(0), left(NULL), right(NULL) {}; }; Node *root; Node* constructTree(vector<int> &nums, int start, int end) { Node* node = new Node(start, end); if (start == end) { node->sum = nums[start]; return node; } int mid = start + (end – start) / 2; node->left = constructTree(nums, start, mid); node->right = constructTree(nums, mid + 1, end); node->sum = node->left->sum + node->right->sum; return node; } int sumRange(int i, int j, Node *root) { if (root == NULL)return 0; if (i == root->start&&j == root->end)return root->sum; int mid = root->start + (root->end – root->start) / 2; if (j <= mid)return sumRange(i, j, root->left); else if (i > mid)return sumRange(i, j, root->right); else return sumRange(i, mid, root->left) + sumRange(mid + 1, j, root->right); } void update(int i, int val, Node *root) { if (root->start == root->end && root->start == i) { root->sum = val; return; } int mid = root->start + (root->end – root->start) / 2; if (i <= mid)update(i, val, root->left); else update(i, val, root->right); root->sum = root->left->sum + root->right->sum; } public: NumArray(vector<int> nums) { root = NULL; if (!nums.empty())root = constructTree(nums, 0, nums.size() – 1); } void update(int i, int val) { if (root == NULL)return; update(i, val, root); } int sumRange(int i, int j) { if (root == NULL)return 0; return sumRange(i, j, root); } }; [/cpp] 本代码提交AC,用时172MS。]]>
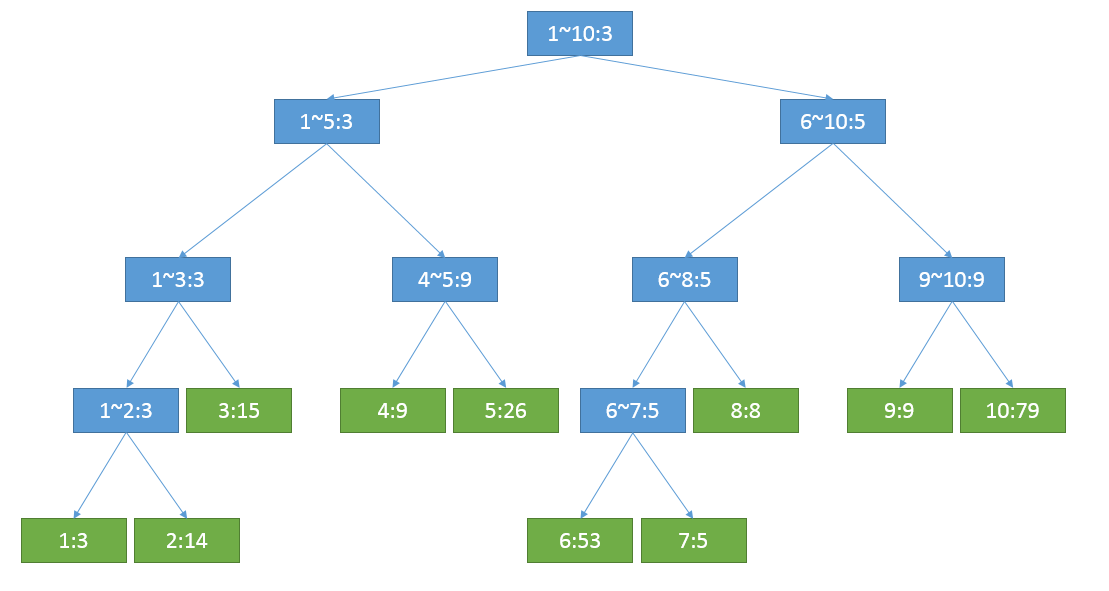 上图是线段树的一个例子,每个节点保存了区间范围以及该区间的最小值。总的区间大小是[1,10],仔细看看这个区间树的节点个数只有19个;另外再画一个[1,6]区间上的区间树,节点个数只有11个。可以不加证明的得出一个n的区间长度的线段树的节点个数为2*n-1,这远远小于n*n,所以我们只需要O(n)的空间来存储,而不是O(n^2)。
反观之前
上图是线段树的一个例子,每个节点保存了区间范围以及该区间的最小值。总的区间大小是[1,10],仔细看看这个区间树的节点个数只有19个;另外再画一个[1,6]区间上的区间树,节点个数只有11个。可以不加证明的得出一个n的区间长度的线段树的节点个数为2*n-1,这远远小于n*n,所以我们只需要O(n)的空间来存储,而不是O(n^2)。
反观之前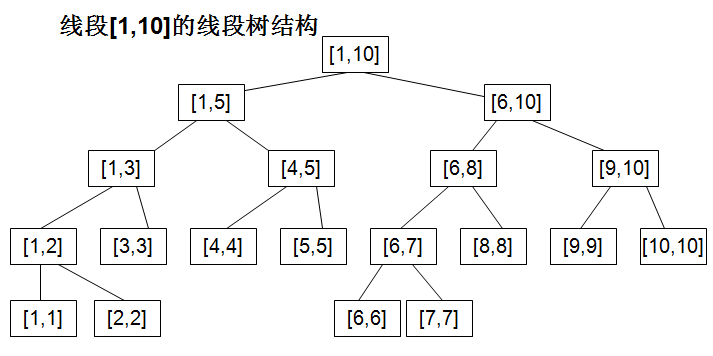 从图中可以看到构造线段树的过程就是一个二分的过程,不断将区间分成两半,直到只有一个元素。图中的线段树每一个节点是一个区间[l,r],本题我稍微改造了一下,改成了数组int seg_tree[left][length],比如seg_tree[i][j]表示从下标i开始,长度为j的这样一个区间上的最小值,这样就可以利用线段树来解决RMQ问题了。比如改造后的线段树就成了下面的样子:
从图中可以看到构造线段树的过程就是一个二分的过程,不断将区间分成两半,直到只有一个元素。图中的线段树每一个节点是一个区间[l,r],本题我稍微改造了一下,改成了数组int seg_tree[left][length],比如seg_tree[i][j]表示从下标i开始,长度为j的这样一个区间上的最小值,这样就可以利用线段树来解决RMQ问题了。比如改造后的线段树就成了下面的样子:
 因为树形这种特殊的结构,我们可以用一个DFS来对树实现二分构造,当DFS到某个节点长度为1时,其最小值就是w[i]本身,在回溯到父节点时,父节那个区间的最小值又是所有子节点最小值中的最小值。因为树的总节点数大约为2*n,所以复杂度O(n)。
当需要查询区间[l,r]的最小值时,只需对数组seg_tree二分搜索。具体来说,假设我们搜索到了节点[s_l,s_len],如果r<(s_l+s_len/2),说明区间[l,r]全在[s_l,s_len]的左边,我们递归在[s_l,s_len/2]区间找;如果l>=(s_l+s_len/2),说明区间[l,r]全在[s_l,s_len]的右边,我们递归在[s_l+s_len/2,s_len-s_len/2]区间找;如果以上两者都不是,说明[l,r]跨界了,而且中点下标一定是s_l+s_len/2,所以我们分别在二两半区间找,然后求这两者的最小值。复杂度O(lgn)。
当需要更新某个下标为pos的值为value时,也是DFS查找线段树,直到找到叶子seg_tree[pos][1],更新它的值,以及所有我们在查找过程经过的父节点的值。复杂度O(lgn)。
所以线段是的性质使得无论是构造、查询、更新操作,复杂度都只要O(lgn),这就是题目中所说的把总的复杂度平均分配到不同操作:平衡乃和谐之理。
完整代码如下:
[cpp]
#include<iostream>
using namespace std;
const int MAX_N=1e4+2;
int w[MAX_N];//每个商品重量
int n,m;
int seg_tree[MAX_N][MAX_N];//seg_tree[i][j]:起点为i,长度为j的区间的最小值
inline int get_min(int a,int b)
{
return a<b?a:b;
}
//深度优先遍历以构造线段树
void dfs(int left,int length)
{
if(length==1)
{
seg_tree[left][1]=w[left];
return;
}
dfs(left,length/2);
dfs(left+length/2,length-length/2);
seg_tree[left][length]=get_min(seg_tree[left][length/2],seg_tree[left+length/2][length-length/2]);//取最小值
}
//在区间[s_left,s_len]搜索区间[left,length]的最小值
int search_min(int s_left,int s_len,int left,int length)
{
if((s_left==left)&&(s_len==length))
return seg_tree[s_left][s_len];
if((left+length-1)<(s_left+s_len/2))//全在左半部分
{
return search_min(s_left,s_len/2,left,length);
}
else if(left>=(s_left+s_len/2))//全在右半部分
{
return search_min(s_left+s_len/2,s_len-s_len/2,left,length);
}
else//左右分开搜索
{
int left_len=s_left+s_len/2-left;
int right_len=length-left_len;
int min_left=search_min(s_left,s_len/2,left,left_len);
int min_right=search_min(s_left+s_len/2,s_len-s_len/2,s_left+s_len/2,right_len);
return get_min(min_left,min_right);
}
}
//从区间[s_left,s_len]开始更新下标pos的值为value
void update(int s_left,int s_len,int pos,int value)
{
if((s_left==pos)&&(s_len==1))
{
seg_tree[s_left][1]=value;
return ;
}
int mid=s_left+s_len/2;
if(pos<mid)
update(s_left,s_len/2,pos,value);
else
update(mid,s_len-s_len/2,pos,value);
seg_tree[s_left][s_len]=get_min(seg_tree[s_left][s_len/2],seg_tree[mid][s_len-s_len/2]);//更新父节点
}
int main()
{
//freopen("input.txt","r",stdin);
cin>>n;
for(int i=1;i<=n;i++)
cin>>w[i];
dfs(1,n);
cin>>m;
int p,l,r;
for(int i=0;i<m;i++)
{
cin>>p>>l>>r;
if(p==0)//查询
{
cout<<search_min(1,n,l,r-l+1)<<endl;
}
else//修改
{
update(1,n,l,r);
}
}
return 0;
}
[/cpp]
本代码提交AC,用时151MS,内存42MB。
]]>
因为树形这种特殊的结构,我们可以用一个DFS来对树实现二分构造,当DFS到某个节点长度为1时,其最小值就是w[i]本身,在回溯到父节点时,父节那个区间的最小值又是所有子节点最小值中的最小值。因为树的总节点数大约为2*n,所以复杂度O(n)。
当需要查询区间[l,r]的最小值时,只需对数组seg_tree二分搜索。具体来说,假设我们搜索到了节点[s_l,s_len],如果r<(s_l+s_len/2),说明区间[l,r]全在[s_l,s_len]的左边,我们递归在[s_l,s_len/2]区间找;如果l>=(s_l+s_len/2),说明区间[l,r]全在[s_l,s_len]的右边,我们递归在[s_l+s_len/2,s_len-s_len/2]区间找;如果以上两者都不是,说明[l,r]跨界了,而且中点下标一定是s_l+s_len/2,所以我们分别在二两半区间找,然后求这两者的最小值。复杂度O(lgn)。
当需要更新某个下标为pos的值为value时,也是DFS查找线段树,直到找到叶子seg_tree[pos][1],更新它的值,以及所有我们在查找过程经过的父节点的值。复杂度O(lgn)。
所以线段是的性质使得无论是构造、查询、更新操作,复杂度都只要O(lgn),这就是题目中所说的把总的复杂度平均分配到不同操作:平衡乃和谐之理。
完整代码如下:
[cpp]
#include<iostream>
using namespace std;
const int MAX_N=1e4+2;
int w[MAX_N];//每个商品重量
int n,m;
int seg_tree[MAX_N][MAX_N];//seg_tree[i][j]:起点为i,长度为j的区间的最小值
inline int get_min(int a,int b)
{
return a<b?a:b;
}
//深度优先遍历以构造线段树
void dfs(int left,int length)
{
if(length==1)
{
seg_tree[left][1]=w[left];
return;
}
dfs(left,length/2);
dfs(left+length/2,length-length/2);
seg_tree[left][length]=get_min(seg_tree[left][length/2],seg_tree[left+length/2][length-length/2]);//取最小值
}
//在区间[s_left,s_len]搜索区间[left,length]的最小值
int search_min(int s_left,int s_len,int left,int length)
{
if((s_left==left)&&(s_len==length))
return seg_tree[s_left][s_len];
if((left+length-1)<(s_left+s_len/2))//全在左半部分
{
return search_min(s_left,s_len/2,left,length);
}
else if(left>=(s_left+s_len/2))//全在右半部分
{
return search_min(s_left+s_len/2,s_len-s_len/2,left,length);
}
else//左右分开搜索
{
int left_len=s_left+s_len/2-left;
int right_len=length-left_len;
int min_left=search_min(s_left,s_len/2,left,left_len);
int min_right=search_min(s_left+s_len/2,s_len-s_len/2,s_left+s_len/2,right_len);
return get_min(min_left,min_right);
}
}
//从区间[s_left,s_len]开始更新下标pos的值为value
void update(int s_left,int s_len,int pos,int value)
{
if((s_left==pos)&&(s_len==1))
{
seg_tree[s_left][1]=value;
return ;
}
int mid=s_left+s_len/2;
if(pos<mid)
update(s_left,s_len/2,pos,value);
else
update(mid,s_len-s_len/2,pos,value);
seg_tree[s_left][s_len]=get_min(seg_tree[s_left][s_len/2],seg_tree[mid][s_len-s_len/2]);//更新父节点
}
int main()
{
//freopen("input.txt","r",stdin);
cin>>n;
for(int i=1;i<=n;i++)
cin>>w[i];
dfs(1,n);
cin>>m;
int p,l,r;
for(int i=0;i<m;i++)
{
cin>>p>>l>>r;
if(p==0)//查询
{
cout<<search_min(1,n,l,r-l+1)<<endl;
}
else//修改
{
update(1,n,l,r);
}
}
return 0;
}
[/cpp]
本代码提交AC,用时151MS,内存42MB。
]]>
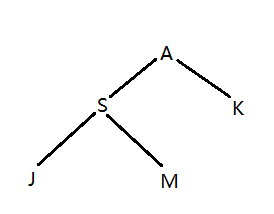 是样例输入构成的一个家谱树,我们常规DFS这个树的序列是这样的:ASJMK。但是本题在进入和离开某个节点时都需要记录下来,而且每访问完一个子节点,要访问下一个子节点时,也需要记录当前父节点。比如访问完J准备访问M时,需要记录S,由此形成的序列为:ASJSMSAKA。
DFS生成的数组B长度大概为边数的两倍,所以复杂度级别只是O(n)的。
DFS之后就把树转换为了数组B[],因为使用RMQ-ST算法需要求某个区间的最小深度节点,所以在DFS的时候还需要记录每个节点的深度信息,而且还要记录每个节点最后访问的下标,这两点都不难,大家直接看代码即可。
RMQ-ST算法
得到数组B后就好办了,可以利用昨天学习的RMQ-ST算法求解2的幂区间长度间深度最小的节点,不过因为我们这题最终输出的是节点的名字而不是节点的深度,所以RMQ-ST比较的是深度,但存储的是节点名。
观察RMQ-ST算法的二重循环知道其复杂度为O(nlgn)。
在线求解
一切准备就绪后就可以求解了,首先根据字符串名字找到对应数字序号,然后查看两节点最后出现在树中的下标l,r,再讲[l,r]区间分成能覆盖[l,r]的2的幂的长度的半区间[l,t]和[t+1,r],最后求这两个区间最小深度的节点,输出其名称。
完整代码如下:
[cpp]
#include<iostream>
#include<map>
#include<string>
#include<vector>
#include<cmath>
using namespace std;
const int MAX_N=100010;//最大人数
map<string,int> name_index;//名字转换为数字
vector<string> index_name(MAX_N);//数字转换为名字
int n,m,k;//k全部记录将树转换成数组tree[]是的下标,转换结束时k即为tree[]的长度
vector<vector<int> > f_s(MAX_N);//f_s[i]表示第i个父亲的所有孩子
int tree[2*MAX_N];//DFS将树转换为的数组
int depth[MAX_N];//每个点在树中的深度
int rmq[MAX_N][30];//区间深度最低值
int last_show[MAX_N];//某个元素最后出现在tree中的位置(下标)
//保存某个人的信息,并返回其下标
int store_name(string name)
{
map<string,int>::iterator it=name_index.find(name);
if(it==name_index.end())//还不存在
{
int curr_index=name_index.size();//用当前已有人数作为其下标,正好是递增的。
name_index.insert(make_pair(name,curr_index));
index_name[curr_index]=name;//记录
return curr_index;//返回下标
}
else
return it->second;//已经存在,直接返回
}
//深度遍历树
void DFS(int root,int deep)
{
tree[k++]=root;//进入即记录
depth[root]=deep;//记录深度
int sons=f_s[root].size();
for(int i=0;i<sons;i++)
{
DFS(f_s[root][i],deep+1);
tree[k++]=root;//每返回一次都要记录一次根节点
}
last_show[root]=k-1;//root节点最后出现的位置
}
//求a,b最小值
inline int get_min(int a,int b)
{
return a<b?a:b;
}
void init_rmq()
{
for(int j=0;j<k;j++)
//rmq[j][0]=depth[tree[j]];
rmq[j][0]=tree[j];//保存的是这个节点,而不是它的深度,方便最后输出
int q=floor(log((double)k)/log(2.0));
for(int i=1;i<=q;i++)
{
for(int j=k-1;j>=0;j–)
{
rmq[j][i]=rmq[j][i-1];
if(j+(1<<(i-1))<k)
{
if(depth[rmq[j+(1<<(i-1))][i-1]]<depth[rmq[j][i]])//+优先级高于<<,所以改j+1<<(i-1)为j+(1<<(i-1))
rmq[j][i]=rmq[j+(1<<(i-1))][i-1];
}
//rmq[j][i]=get_min(rmq[j][i],rmq[j+1<<(i-1)][i-1]);
}
}
}
int main()
{
//freopen("input.txt","r",stdin);
cin>>n;
string name1,name2;
int index1,index2;
while(n–)
{
cin>>name1>>name2;
index1=store_name(name1);
index2=store_name(name2);
f_s[index1].push_back(index2);
}
k=0;//开始时树的下标为0,DFS完之后正好是tree[]数组的长度,可以作为rmq-st的n
DFS(0,0);
init_rmq();
cin>>m;
int l,r,t;
while(m–)
{
cin>>name1>>name2;
if(name1==name2)
{
cout<<name1<<endl;
continue;
}
index1=store_name(name1);
index2=store_name(name2);
l=last_show[index1];
r=last_show[index2];
if(l>r)//保证l<=r
{
int tmp=r;
r=l;
l=tmp;
}
t=floor(log(double(r-l+1))/log(2.0));//找到能使[l,r]分为两半的指数
cout<<index_name[get_min(rmq[l][t],rmq[r-(1<<t)+1][t])]<<endl;//r-(1<<t)+1,记得+1
}
return 0;
}
[/cpp]
本代码提交AC,用时202MS,内存8MB。
相比于
是样例输入构成的一个家谱树,我们常规DFS这个树的序列是这样的:ASJMK。但是本题在进入和离开某个节点时都需要记录下来,而且每访问完一个子节点,要访问下一个子节点时,也需要记录当前父节点。比如访问完J准备访问M时,需要记录S,由此形成的序列为:ASJSMSAKA。
DFS生成的数组B长度大概为边数的两倍,所以复杂度级别只是O(n)的。
DFS之后就把树转换为了数组B[],因为使用RMQ-ST算法需要求某个区间的最小深度节点,所以在DFS的时候还需要记录每个节点的深度信息,而且还要记录每个节点最后访问的下标,这两点都不难,大家直接看代码即可。
RMQ-ST算法
得到数组B后就好办了,可以利用昨天学习的RMQ-ST算法求解2的幂区间长度间深度最小的节点,不过因为我们这题最终输出的是节点的名字而不是节点的深度,所以RMQ-ST比较的是深度,但存储的是节点名。
观察RMQ-ST算法的二重循环知道其复杂度为O(nlgn)。
在线求解
一切准备就绪后就可以求解了,首先根据字符串名字找到对应数字序号,然后查看两节点最后出现在树中的下标l,r,再讲[l,r]区间分成能覆盖[l,r]的2的幂的长度的半区间[l,t]和[t+1,r],最后求这两个区间最小深度的节点,输出其名称。
完整代码如下:
[cpp]
#include<iostream>
#include<map>
#include<string>
#include<vector>
#include<cmath>
using namespace std;
const int MAX_N=100010;//最大人数
map<string,int> name_index;//名字转换为数字
vector<string> index_name(MAX_N);//数字转换为名字
int n,m,k;//k全部记录将树转换成数组tree[]是的下标,转换结束时k即为tree[]的长度
vector<vector<int> > f_s(MAX_N);//f_s[i]表示第i个父亲的所有孩子
int tree[2*MAX_N];//DFS将树转换为的数组
int depth[MAX_N];//每个点在树中的深度
int rmq[MAX_N][30];//区间深度最低值
int last_show[MAX_N];//某个元素最后出现在tree中的位置(下标)
//保存某个人的信息,并返回其下标
int store_name(string name)
{
map<string,int>::iterator it=name_index.find(name);
if(it==name_index.end())//还不存在
{
int curr_index=name_index.size();//用当前已有人数作为其下标,正好是递增的。
name_index.insert(make_pair(name,curr_index));
index_name[curr_index]=name;//记录
return curr_index;//返回下标
}
else
return it->second;//已经存在,直接返回
}
//深度遍历树
void DFS(int root,int deep)
{
tree[k++]=root;//进入即记录
depth[root]=deep;//记录深度
int sons=f_s[root].size();
for(int i=0;i<sons;i++)
{
DFS(f_s[root][i],deep+1);
tree[k++]=root;//每返回一次都要记录一次根节点
}
last_show[root]=k-1;//root节点最后出现的位置
}
//求a,b最小值
inline int get_min(int a,int b)
{
return a<b?a:b;
}
void init_rmq()
{
for(int j=0;j<k;j++)
//rmq[j][0]=depth[tree[j]];
rmq[j][0]=tree[j];//保存的是这个节点,而不是它的深度,方便最后输出
int q=floor(log((double)k)/log(2.0));
for(int i=1;i<=q;i++)
{
for(int j=k-1;j>=0;j–)
{
rmq[j][i]=rmq[j][i-1];
if(j+(1<<(i-1))<k)
{
if(depth[rmq[j+(1<<(i-1))][i-1]]<depth[rmq[j][i]])//+优先级高于<<,所以改j+1<<(i-1)为j+(1<<(i-1))
rmq[j][i]=rmq[j+(1<<(i-1))][i-1];
}
//rmq[j][i]=get_min(rmq[j][i],rmq[j+1<<(i-1)][i-1]);
}
}
}
int main()
{
//freopen("input.txt","r",stdin);
cin>>n;
string name1,name2;
int index1,index2;
while(n–)
{
cin>>name1>>name2;
index1=store_name(name1);
index2=store_name(name2);
f_s[index1].push_back(index2);
}
k=0;//开始时树的下标为0,DFS完之后正好是tree[]数组的长度,可以作为rmq-st的n
DFS(0,0);
init_rmq();
cin>>m;
int l,r,t;
while(m–)
{
cin>>name1>>name2;
if(name1==name2)
{
cout<<name1<<endl;
continue;
}
index1=store_name(name1);
index2=store_name(name2);
l=last_show[index1];
r=last_show[index2];
if(l>r)//保证l<=r
{
int tmp=r;
r=l;
l=tmp;
}
t=floor(log(double(r-l+1))/log(2.0));//找到能使[l,r]分为两半的指数
cout<<index_name[get_min(rmq[l][t],rmq[r-(1<<t)+1][t])]<<endl;//r-(1<<t)+1,记得+1
}
return 0;
}
[/cpp]
本代码提交AC,用时202MS,内存8MB。
相比于