hihoCoder 1519-逃离迷宫II
#1519 : 逃离迷宫II
时间限制:10000ms
单点时限:1000ms
内存限制:256MB
描述
小Hi被坏女巫抓进里一间有N x M个格子组成的矩阵迷宫。
有些格子是小Hi可以经过的,我们用’.’表示;有些格子上有障碍物小Hi不能经过,我们用’#’表示。小Hi的起始位置用’S’表示,他需要到达用’T’表示的格子才能逃离迷宫。
麻烦的是小Hi被坏女巫施了魔法,他只能选择上下左右某一个方向,沿着这个方向一直走,直到遇到障碍物或者迷宫边界才能改变方向。新的方向可以是上下左右四个方向之一。之后他还是只能沿着新的方向一直走直到再次遇到障碍物或者迷宫边界……
小Hi想知道他最少改变几次方向才能逃离这个迷宫。
输入
第一行包含两个整数N和M。 (1 <= N, M <= 500)
以下N行每行M个字符,代表迷宫。
输出
一个整数代表答案。如果小Hi没法逃离迷宫,输出-1。
- 样例输入
-
5 5
S.#.T
.....
.....
.....
.....
- 样例输出
-
2
给定一个迷宫,S表示起点,T表示终点,#表示障碍物。行走的时候,只能沿着直线走,直到遇到障碍物或者碰壁,问从S到T,最少需要改变多少次方向。
我一开始是用DFS做的,每次朝一个方向DFS下去,但是因为每次DFS时走了一长条直线,所以回溯的时候需要把之前走过的直线复位。代码如下:
[cpp]
#include<iostream>
#include<vector>
#include<climits>
#include<algorithm>
#include<set>
#include<unordered_set>
#include<unordered_map>
#include<cmath>
using namespace std;
const int MAXN = 505;
int n, m;
int startx, starty, endx, endy;
int ans = INT_MAX;
vector<vector<char>> maze(MAXN, vector<char>(MAXN, ‘0’));
vector<vector<char>> visited(MAXN, vector<char>(MAXN, ‘0’));
vector<vector<int>> dirs{ {-1,0},{1,0},{0,-1},{0,1} }; //up,down,left,right
vector<vector<int>> opdirs{ { 1,0 },{ -1,0 },{ 0,1 },{ 0,-1 } }; // 反方向
bool ok(int x, int y) {
if (x >= 0 && x < n&&y >= 0 && y < m&&maze[x][y] != ‘#’)return true;
return false;
}
void dfs(int sx,int sy, int step) {
for (int i = 0; i < 4; ++i) {
int newx = sx + dirs[i][0], newy = sy + dirs[i][1];
if (ok(newx, newy) && visited[newx][newy] == ‘0’) {
visited[newx][newy] = ‘1’;
bool done = false;
while (ok(newx, newy)) {
visited[newx][newy] = ‘1’;
if (newx == endx&&newy == endy) {
done = true;
break;
}
newx = newx + dirs[i][0], newy = newy + dirs[i][1];
}
if (done) {
ans = min(ans, step);
}
else {
dfs(newx + opdirs[i][0], newy + opdirs[i][1], step + 1); // 往回走一步再递归
}
while (!(newx == sx&&newy == sy)) {
if (ok(newx, newy))visited[newx][newy] = ‘0’; // 复位
newx = newx + opdirs[i][0], newy = newy + opdirs[i][1];
}
}
}
}
int main() {
//freopen("input.txt", "r", stdin);
scanf("%d %d", &n, &m);
char c;
for (int i = 0; i < n; ++i) {
scanf("%c", &c);
for (int j = 0; j < m; ++j) {
scanf("%c", &maze[i][j]);
if (maze[i][j] == ‘S’) {
startx = i;
starty = j;
}
else if (maze[i][j] == ‘T’) {
endx = i;
endy = j;
}
}
}
visited[startx][starty] = ‘1’;
dfs(startx, starty, 0);
if (ans == INT_MAX)printf("-1\n");
else printf("%d\n", ans);
return 0;
}
[/cpp]
本代码提交TLE,很明显会TLE,因为DFS必须把所有方案都走一遍才能得到最小值。
比赛的时候脑子短路,这种搜索问题要求最短XX的肯定用BFS比DFS快呀,因为第一次BFS到的方案肯定就是最优方案呀。只不过这题判断距离用的是转弯次数,以前都是算走过的步数。
对于这题,用BFS也是一样的,BFS的下一个点肯定就是走直线走到无法再走的那个拐角点(cornor)。不过为了防止死循环,要把以前走过的拐角都记录下来,只走那些以前没走过的拐点。
代码如下:
[cpp]
#include<iostream>
#include<vector>
#include<climits>
#include<algorithm>
#include<set>
#include<unordered_set>
#include<unordered_map>
#include<cmath>
#include<queue>
using namespace std;
const int MAXN = 505;
int n, m;
int startx, starty, endx, endy;
typedef struct P {
int x, y, step;
P(int x_, int y_, int step_) :x(x_), y(y_), step(step_) {};
};
vector<vector<char>> maze(MAXN, vector<char>(MAXN, ‘0’));
vector<vector<int>> dirs{ { -1,0 },{ 1,0 },{ 0,-1 },{ 0,1 } }; //up,down,left,right
vector<vector<int>> opdirs{ { 1,0 },{ -1,0 },{ 0,1 },{ 0,-1 } }; // 反方向
set<int> points;
bool ok(int x, int y) {
if (x >= 0 && x < n&&y >= 0 && y < m&&maze[x][y] != ‘#’)return true;
return false;
}
int id(int x, int y) {
return x*n + y;
}
int bfs() {
queue<P> q;
P p(startx, starty, 0);
q.push(p);
while (!q.empty()) {
p = q.front();
q.pop();
points.insert(id(p.x, p.y));
for (int i = 0; i < dirs.size(); ++i) {
int newx = p.x + dirs[i][0], newy = p.y + dirs[i][1];
while (ok(newx, newy)) {
if (newx == endx&&newy == endy) {
return p.step;
}
newx = newx + dirs[i][0], newy = newy + dirs[i][1];
}
int cornorx = newx + opdirs[i][0], cornory = newy + opdirs[i][1]; // 往回走一步
if (points.find(id(cornorx, cornory)) == points.end()) {
P tmp(cornorx, cornory, p.step + 1);
q.push(tmp);
}
}
}
return -1;
}
int main() {
//freopen("input.txt", "r", stdin);
scanf("%d %d", &n, &m);
char c;
for (int i = 0; i < n; ++i) {
scanf("%c", &c);
for (int j = 0; j < m; ++j) {
scanf("%c", &maze[i][j]);
if (maze[i][j] == ‘S’) {
startx = i;
starty = j;
}
else if (maze[i][j] == ‘T’) {
endx = i;
endy = j;
}
}
}
printf("%d\n", bfs());
return 0;
}
[/cpp]
本代码提交AC,用时718MS。]]>


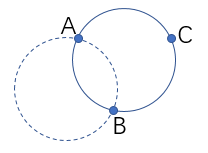 已知两点求圆心的方法请看
已知两点求圆心的方法请看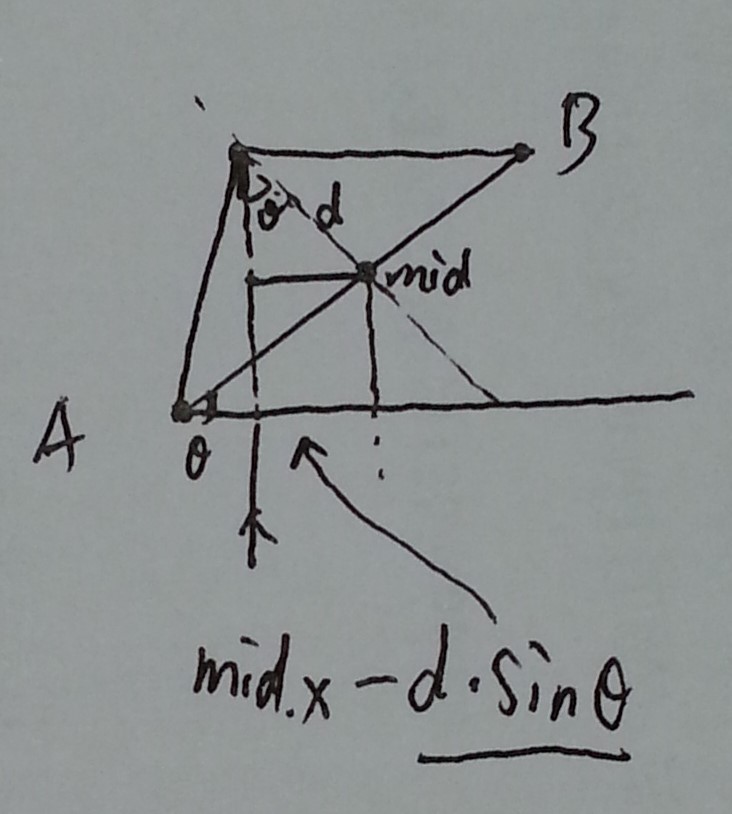 暴力方法在hiho上TLE,需要寻求更高效的算法。
假设以两个点i,j为圆心画半径为R的圆,如果两个圆相交,则在相交的弧上任意一点画圆,都能覆盖原来的i,j两点。基于这个思想,假设现在固定点i为圆心,R为半径画圆,求出所有以其他点为圆心画的圆和圆i相交的弧,则在相交重叠次数最多的那段弧上的点为圆心画的圆肯定能覆盖最多的点,覆盖的点数就是这段弧被重叠的次数。每个点i都能求出这样一个最大值,则所有点的这个最大值的最大值就是全局能覆盖的最多点。
怎样表示两个圆相交的那段弧呢,使用极坐标,因为弧是由两条半径张成的,所以可以表示成两条半径的极坐标夹角,并且标明夹角的开始(is=1)和结束(is=-1)。求重叠次数最多的弧的方法是,把所有重叠弧的起止半径的极坐标夹角排个序,然后遍历一下,当夹角开始(is=1)次数最多且结束(is=-1)次数最少时,说明重叠次数最多,所以就是is的累加和的最大值。
完整代码借鉴
暴力方法在hiho上TLE,需要寻求更高效的算法。
假设以两个点i,j为圆心画半径为R的圆,如果两个圆相交,则在相交的弧上任意一点画圆,都能覆盖原来的i,j两点。基于这个思想,假设现在固定点i为圆心,R为半径画圆,求出所有以其他点为圆心画的圆和圆i相交的弧,则在相交重叠次数最多的那段弧上的点为圆心画的圆肯定能覆盖最多的点,覆盖的点数就是这段弧被重叠的次数。每个点i都能求出这样一个最大值,则所有点的这个最大值的最大值就是全局能覆盖的最多点。
怎样表示两个圆相交的那段弧呢,使用极坐标,因为弧是由两条半径张成的,所以可以表示成两条半径的极坐标夹角,并且标明夹角的开始(is=1)和结束(is=-1)。求重叠次数最多的弧的方法是,把所有重叠弧的起止半径的极坐标夹角排个序,然后遍历一下,当夹角开始(is=1)次数最多且结束(is=-1)次数最少时,说明重叠次数最多,所以就是is的累加和的最大值。
完整代码借鉴