You are given an undirected weighted graph of n nodes (0-indexed), represented by an edge list where edges[i] = [a, b] is an undirected edge connecting the nodes a and b with a probability of success of traversing that edge succProb[i].
Given two nodes start and end, find the path with the maximum probability of success to go from start to end and return its success probability.
If there is no path from start to end, return 0. Your answer will be accepted if it differs from the correct answer by at most 1e-5.
Example 1:
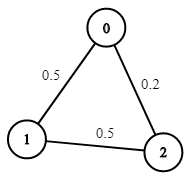
Input: n = 3, edges = [[0,1],[1,2],[0,2]], succProb = [0.5,0.5,0.2], start = 0, end = 2
Output: 0.25000
Explanation: There are two paths from start to end, one having a probability of success = 0.2 and the other has 0.5 * 0.5 = 0.25.
Example 2:
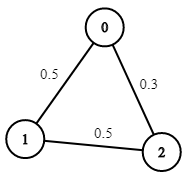
Input: n = 3, edges = [[0,1],[1,2],[0,2]], succProb = [0.5,0.5,0.3], start = 0, end = 2
Output: 0.30000
Example 3:
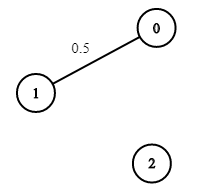
Input: n = 3, edges = [[0,1]], succProb = [0.5], start = 0, end = 2
Output: 0.00000
Explanation: There is no path between 0 and 2.
Constraints:
2 <= n <= 10^4
0 <= start, end < n
start != end
0 <= a, b < n
a != b
0 <= succProb.length == edges.length <= 2*10^4
0 <= succProb[i] <= 1
There is at most one edge between every two nodes.
给定一个无向图,边表示概率,问从start到end的最大概率是多少。
借此题复习一下若干最短路径算法吧。
首先朴素的DFS,代码如下:
class Solution {
private:
void DFS(const vector<vector<double>> &graph, vector<int> &visited, int start, int end, double curprob, double &maxprob) {
if (start == end) {
maxprob = max(maxprob, curprob);
return;
}
int n = graph.size();
for (int i = 0; i < n; ++i) {
if (visited[i] == 0 && graph[start][i] >= 0) {
visited[i] = 1;
DFS(graph, visited, i, end, curprob*graph[start][i], maxprob);
visited[i] = 0;
}
}
}
public:
double maxProbability(int n, vector<vector<int>>& edges, vector<double>& succProb, int start, int end) {
vector<vector<double>> graph(n, vector<double>(n, -1.0));
for (int i = 0; i < edges.size(); ++i) {
graph[edges[i][0]][edges[i][1]] = succProb[i];
graph[edges[i][1]][edges[i][0]] = succProb[i];
}
vector<int> visited(n, 0);
visited[start] = 1;
double maxprob = 0;
DFS(graph, visited, start, end, 1, maxprob);
return maxprob;
}
};
class Solution {
public:
int minJump(vector<int>& jump) {
int n = jump.size();
vector<int> visited(n, 0);
visited[0] = 1;
queue<int> q;
q.push(0);
int steps = 0;
int premax = 0;
while (!q.empty()) {
++steps;
int sz = q.size();
while (sz--) {
int cur = q.front();
q.pop();
int next = cur + jump[cur];
if (next >= n)return steps;
if (visited[next] == 0) {
q.push(next);
}
for (int pre = premax; pre < cur; ++pre) {
if (visited[pre] == 0) {
visited[pre] = 1;
q.push(pre);
}
}
premax = max(premax, cur);
}
}
return 0;
}
};
class Solution {
public:
int numWays(int n, vector<vector<int>>& relation, int k) {
vector<vector<int>> graph(n, vector<int>(n, 0));
for (int i = 0; i < relation.size(); ++i) {
graph[relation[i][0]][relation[i][1]] = 1;
}
queue<pair<int, int>> q;
q.push(make_pair(0, 0));
int ans = 0;
while (!q.empty()) {
pair<int, int> p = q.front();
q.pop();
if (p.first == n - 1 && p.second == k)++ans;
if (p.second < k) {
for (int i = 0; i < n; ++i) {
if (graph[p.first][i] == 1) {
q.push(make_pair(i, p.second + 1));
}
}
}
}
return ans;
}
};
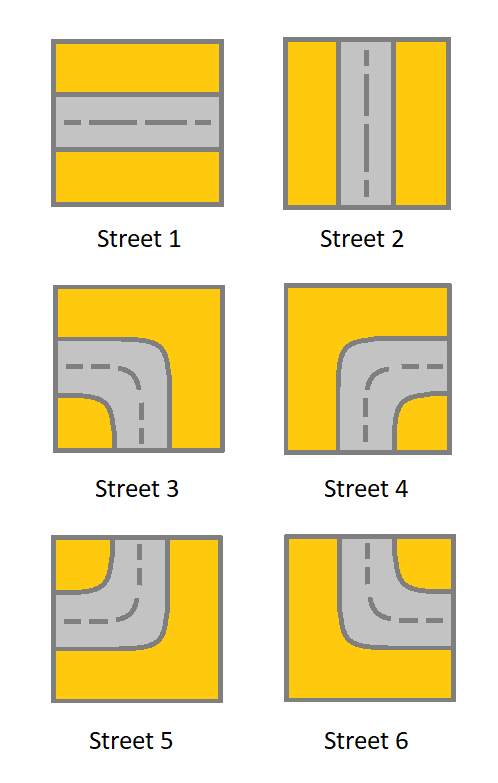
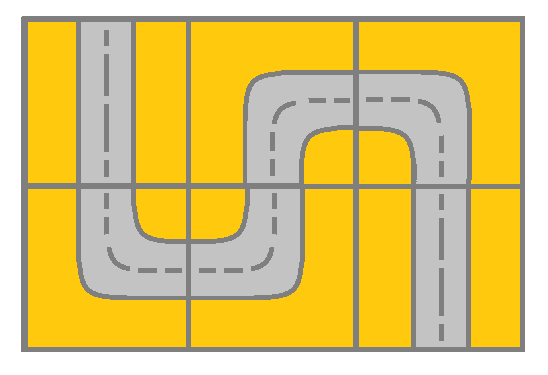
Given a m x ngrid. Each cell of the grid represents a street. The street of grid[i][j] can be:
1 which means a street connecting the left cell and the right cell.
2 which means a street connecting the upper cell and the lower cell.
3 which means a street connecting the left cell and the lower cell.
4 which means a street connecting the right cell and the lower cell.
5 which means a street connecting the left cell and the upper cell.
6 which means a street connecting the right cell and the upper cell.
You will initially start at the street of the upper-left cell (0,0). A valid path in the grid is a path which starts from the upper left cell (0,0) and ends at the bottom-right cell (m - 1, n - 1). The path should only follow the streets.
Notice that you are not allowed to change any street.
Return true if there is a valid path in the grid or false otherwise.
Example 1:
Input: grid = [[2,4,3],[6,5,2]]
Output: true
Explanation: As shown you can start at cell (0, 0) and visit all the cells of the grid to reach (m - 1, n - 1).
Example 2:
Input: grid = [[1,2,1],[1,2,1]]
Output: false
Explanation: As shown you the street at cell (0, 0) is not connected with any street of any other cell and you will get stuck at cell (0, 0)
Example 3:
Input: grid = [[1,1,2]]
Output: false
Explanation: You will get stuck at cell (0, 1) and you cannot reach cell (0, 2).
Given an undirected tree consisting of n vertices numbered from 1 to n. A frog starts jumping from the vertex 1. In one second, the frog jumps from its current vertex to another unvisited vertex if they are directly connected. The frog can not jump back to a visited vertex. In case the frog can jump to several vertices it jumps randomly to one of them with the same probability, otherwise, when the frog can not jump to any unvisited vertex it jumps forever on the same vertex.
The edges of the undirected tree are given in the array edges, where edges[i] = [fromi, toi] means that exists an edge connecting directly the vertices fromi and toi.
Return the probability that after t seconds the frog is on the vertex target.
Example 1:
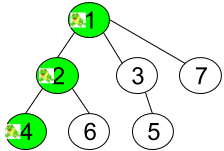
Input: n = 7, edges = [[1,2],[1,3],[1,7],[2,4],[2,6],[3,5]], t = 2, target = 4
Output: 0.16666666666666666
Explanation: The figure above shows the given graph. The frog starts at vertex 1, jumping with 1/3 probability to the vertex 2 after second 1 and then jumping with 1/2 probability to vertex 4 after second 2. Thus the probability for the frog is on the vertex 4 after 2 seconds is 1/3 * 1/2 = 1/6 = 0.16666666666666666.
Example 2:
Input: n = 7, edges = [[1,2],[1,3],[1,7],[2,4],[2,6],[3,5]], t = 1, target = 7
Output: 0.3333333333333333
Explanation: The figure above shows the given graph. The frog starts at vertex 1, jumping with 1/3 = 0.3333333333333333 probability to the vertex 7 after second 1.
Example 3:
Input: n = 7, edges = [[1,2],[1,3],[1,7],[2,4],[2,6],[3,5]], t = 20, target = 6
Output: 0.16666666666666666
Constraints:
1 <= n <= 100
edges.length == n-1
edges[i].length == 2
1 <= edges[i][0], edges[i][1] <= n
1 <= t <= 50
1 <= target <= n
Answers within 10^-5 of the actual value will be accepted as correct.
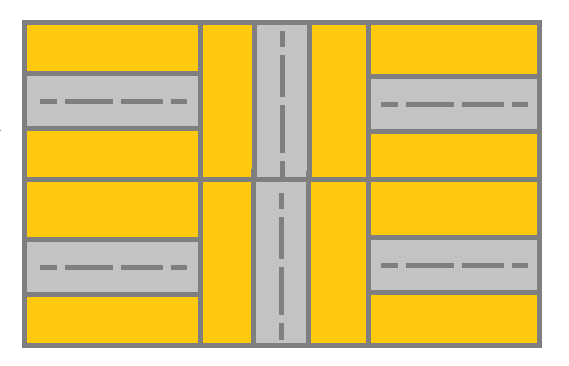
Given a m x ngrid. Each cell of the grid has a sign pointing to the next cell you should visit if you are currently in this cell. The sign of grid[i][j] can be:
1 which means go to the cell to the right. (i.e go from grid[i][j] to grid[i][j + 1])
2 which means go to the cell to the left. (i.e go from grid[i][j] to grid[i][j - 1])
3 which means go to the lower cell. (i.e go from grid[i][j] to grid[i + 1][j])
4 which means go to the upper cell. (i.e go from grid[i][j] to grid[i - 1][j])
Notice that there could be some invalid signs on the cells of the grid which points outside the grid.
You will initially start at the upper left cell (0,0). A valid path in the grid is a path which starts from the upper left cell (0,0) and ends at the bottom-right cell (m - 1, n - 1) following the signs on the grid. The valid path doesn’t have to be the shortest.
You can modify the sign on a cell with cost = 1. You can modify the sign on a cell one time only.
Return the minimum cost to make the grid have at least one valid path.
Example 1:
Input: grid = [[1,1,1,1],[2,2,2,2],[1,1,1,1],[2,2,2,2]]
Output: 3
Explanation: You will start at point (0, 0).
The path to (3, 3) is as follows. (0, 0) --> (0, 1) --> (0, 2) --> (0, 3) change the arrow to down with cost = 1 --> (1, 3) --> (1, 2) --> (1, 1) --> (1, 0) change the arrow to down with cost = 1 --> (2, 0) --> (2, 1) --> (2, 2) --> (2, 3) change the arrow to down with cost = 1 --> (3, 3)
The total cost = 3.
Example 2:
Input: grid = [[1,1,3],[3,2,2],[1,1,4]]
Output: 0
Explanation: You can follow the path from (0, 0) to (2, 2).
struct Node {
int x, y, cost;
Node() :x(0), y(0), cost(0) {};
Node(int x_, int y_, int cost_) :x(x_), y(y_), cost(cost_) {};
};
class Solution {
public:
int minCost(vector<vector<int>>& grid) {
vector<vector<int>> dirs = { {0, 1}, {0, -1},{1, 0},{-1, 0} };//右左下上
int m = grid.size(), n = grid[0].size();
vector<vector<int>> flag(m, vector<int>(n, 0));
deque<Node> q;
q.push_back(Node());
int ans = 0;
while (!q.empty()) {
Node cur = q.front();
q.pop_front();
flag[cur.x][cur.y] = 1;
if (cur.x == m - 1 && cur.y == n - 1) {
ans = cur.cost;
break;
}
for (int i = 0; i < dirs.size(); ++i) {
int x = cur.x + dirs[i][0], y = cur.y + dirs[i][1];
if (x < 0 || x >= m || y < 0 || y >= n)continue;
if (flag[x][y] == 1)continue;
if (i + 1 == grid[cur.x][cur.y]) {
q.push_front(Node(x, y, cur.cost));
}
else {
q.push_back(Node(x, y, cur.cost + 1));
}
}
}
return ans;
}
};
LeetCode 2 Keys Keyboard
Initially on a notepad only one character ‘A’ is present. You can perform two operations on this notepad for each step:
Copy All: You can copy all the characters present on the notepad (partial copy is not allowed).
Paste: You can paste the characters which are copied last time.
Given a number n. You have to get exactlyn ‘A’ on the notepad by performing the minimum number of steps permitted. Output the minimum number of steps to get n ‘A’.
Example 1:
Input: 3
Output: 3
Explanation:
Intitally, we have one character 'A'.
In step 1, we use Copy All operation.
In step 2, we use Paste operation to get 'AA'.
In step 3, we use Paste operation to get 'AAA'.
Note:
The n will be in the range [1, 1000].
一个记事本中原本只有一个字符A,每次可以做两种操作中的一种,分别是全选和粘贴。问要得到n个字符A,至少需要经过多少次操作。
这一题我一开始想到用BFS来做,两种操作相当于两条搜索路径,所以很容易能写出BFS的代码:
[cpp]
class Solution {
private:
struct Node {
int presented_cnt_; // 现在有多少个字符
int copied_cnt_; // 剪切板中有多少个字符
int step_; // 走过多少步了
Node(int p, int c, int s) :presented_cnt_(p), copied_cnt_(c), step_(s) {};
};
public:
int minSteps(int n) {
queue<Node> q;
Node node(1, 0, 0);
q.push(node);
while (!q.empty()) {
Node cur = q.front();
q.pop();
if (cur.presented_cnt_ == n)
return cur.step_;
if (cur.presented_cnt_ > n)continue;
Node copy_node(cur.presented_cnt_, cur.presented_cnt_, cur.step_ + 1); // 全选
q.push(copy_node);
if (cur.copied_cnt_ != 0) { // 粘贴
Node paste_node(cur.presented_cnt_ + cur.copied_cnt_, cur.copied_cnt_, cur.step_ + 1);
q.push(paste_node);
}
}
}
};
[/cpp]
预料到了,本代码提交TLE。
搜索会超时的,用DP一般都不会超时。设dp[i]表示要得到i个字符A,至少需要的操作数。显然,dp[1]=0。
假设已经求到了dp[1,…,i-1],现在要求dp[i]。要得到i个字符,最多的操作数是i,即先复制一个A,然后粘贴i-1次,总共需要i次操作。比较快的方法是,如果i是偶数,则可以从i/2个字符开始,全选粘贴就能得到i个字符。
所以我们遍历i前面的所有j,如果i能整除j,则可以全选j,然后粘贴i/j-1次得到i个字符,即操作数是1+(i/j-1)=i/j,当然还需要加上到达i的操作数,所以dp[j]=dp[i]+i/j。
完整代码如下:
[cpp]
class Solution {
public:
int minSteps(int n) {
vector<int> dp(n + 1, INT_MAX);
dp[1] = 0;
for (int i = 2; i <= n; ++i) {
dp[i] = i;
for (int j = i – 1; j >= 1; –j) {
if (i%j == 0) {
dp[i] = min(dp[i], dp[j] + i / j);
}
}
}
return dp[n];
}
};
[/cpp]
本代码提交AC,用时79MS。
还有一种解法类似于素数筛法,我们首先知道dp[1]=0,如果我们对1个字符先全选,然后不停粘贴,则能得到2,3,4,…个字符,且操作数是2,3,4,…;下一次,我们知道dp[2]=2,如果我们对2个字符全选,然后不停粘贴,则能得到4,6,8,…个字符,且操作数是4,5,6,…。每一轮我们都只保留最小操作数。最终筛完之后,就是全局最优结果了。
完整代码如下:
[cpp]
class Solution {
public:
int minSteps(int n) {
vector<int> dp(n + 1, INT_MAX);
dp[1] = 0;
for (int i = 1; i <= n; ++i) {
for (int j = 2 * i, k = 2; j <= n; j += i, ++k) {
dp[j] = min(dp[j], dp[i] + k);
}
}
return dp[n];
}
};
[/cpp]
本代码提交AC,用时3MS,速度飞快,因为越到后面,循环倍数越少。]]>
LeetCode Average of Levels in Binary Tree
Given a non-empty binary tree, return the average value of the nodes on each level in the form of an array.
Example 1:
Input:
3
/ \
9 20
/ \
15 7
Output: [3, 14.5, 11]
Explanation:
The average value of nodes on level 0 is 3, on level 1 is 14.5, and on level 2 is 11. Hence return [3, 14.5, 11].
Note:
The range of node’s value is in the range of 32-bit signed integer.
求二叉树每一层的平均数。简单题,BFS层次遍历。代码如下:
[cpp]
class Solution {
public:
vector<double> averageOfLevels(TreeNode* root) {
if (root == NULL)return{};
vector<double> ans;
queue<TreeNode*> q;
q.push(root);
while (!q.empty()) {
double sum = 0;
size_t n = q.size();
for (size_t i = 0; i < n; ++i) {
TreeNode* f = q.front();
q.pop();
sum += f->val;
if (f->left != NULL)q.push(f->left);
if (f->right != NULL)q.push(f->right);
}
ans.push_back(sum / n);
}
return ans;
}
};
[/cpp]
本代码提交AC,用时15MS。]]>