You are given coins of different denominations and a total amount of money. Write a function to compute the number of combinations that make up that amount. You may assume that you have infinite number of each kind of coin.
Example 1:
Input: amount = 5, coins = [1, 2, 5]
Output: 4
Explanation: there are four ways to make up the amount:
5=5
5=2+2+1
5=2+1+1+1
5=1+1+1+1+1
Example 2:
Input: amount = 3, coins = [2]
Output: 0
Explanation: the amount of 3 cannot be made up just with coins of 2.
Example 3:
Input: amount = 10, coins = [10]
Output: 1
Note:
You can assume that
0 <= amount <= 5000
1 <= coin <= 5000
the number of coins is less than 500
the answer is guaranteed to fit into signed 32-bit integer
Given the root of a binary tree and an integer distance. A pair of two different leaf nodes of a binary tree is said to be good if the length of the shortest path between them is less than or equal to distance.
Return the number of good leaf node pairs in the tree.
Example 1:
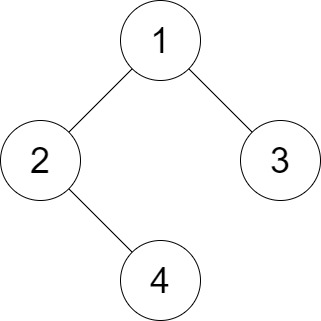
Input: root = [1,2,3,null,4], distance = 3
Output: 1
Explanation: The leaf nodes of the tree are 3 and 4 and the length of the shortest path between them is 3. This is the only good pair.
Example 2:
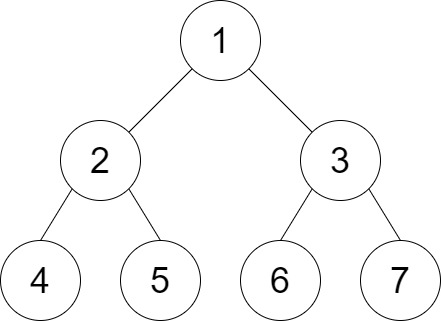
Input: root = [1,2,3,4,5,6,7], distance = 3
Output: 2
Explanation: The good pairs are [4,5] and [6,7] with shortest path = 2. The pair [4,6] is not good because the length of ther shortest path between them is 4.
Example 3:
Input: root = [7,1,4,6,null,5,3,null,null,null,null,null,2], distance = 3
Output: 1
Explanation: The only good pair is [2,5].
Example 4:
Input: root = [100], distance = 1
Output: 0
Example 5:
Input: root = [1,1,1], distance = 2
Output: 1
Constraints:
The number of nodes in the tree is in the range [1, 2^10].
There is a room with n bulbs, numbered from 0 to n-1, arranged in a row from left to right. Initially all the bulbs are turned off.
Your task is to obtain the configuration represented by target where target[i] is ‘1’ if the i-th bulb is turned on and is ‘0’ if it is turned off.
You have a switch to flip the state of the bulb, a flip operation is defined as follows:
Choose any bulb (index i) of your current configuration.
Flip each bulb from index i to n-1.
When any bulb is flipped it means that if it is 0 it changes to 1 and if it is 1 it changes to 0.
Return the minimum number of flips required to form target.
Example 1:
Input: target = "10111"
Output: 3
Explanation: Initial configuration "00000".
flip from the third bulb: "00000" -> "00111"
flip from the first bulb: "00111" -> "11000"
flip from the second bulb: "11000" -> "10111"
We need at least 3 flip operations to form target.
class Solution {
public:
int minFlips(string target) {
int n = target.size();
int ans = 0;
int i = 0;
while (i < n) {
int j = i + 1;
while (j < n&&target[j] == target[i])++j;
++ans;
i = j;
}
if (target[0] == '0')return ans - 1;
else return ans;
}
};
Given a string s and an integer array indices of the same length.
The string s will be shuffled such that the character at the ith position moves to indices[i] in the shuffled string.
Return the shuffled string.
Example 1:
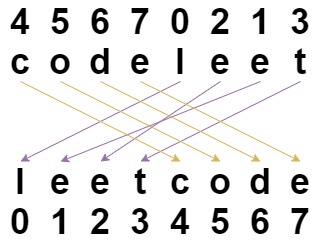
Input: s = "codeleet", indices = [4,5,6,7,0,2,1,3]
Output: "leetcode"
Explanation: As shown, "codeleet" becomes "leetcode" after shuffling.
Example 2:
Input: s = "abc", indices = [0,1,2]
Output: "abc"
Explanation: After shuffling, each character remains in its position.
Example 3:
Input: s = "aiohn", indices = [3,1,4,2,0]
Output: "nihao"
Example 4:
Input: s = "aaiougrt", indices = [4,0,2,6,7,3,1,5]
Output: "arigatou"
Example 5:
Input: s = "art", indices = [1,0,2]
Output: "rat"
Constraints:
s.length == indices.length == n
1 <= n <= 100
s contains only lower-case English letters.
0 <= indices[i] < n
All values of indices are unique (i.e. indices is a permutation of the integers from 0 to n - 1).
给定一个字符串,根据给定规则进行shuffle,直接照做。代码如下:
class Solution {
public:
string restoreString(string s, vector<int>& indices) {
int n = s.size();
string ans = s;
for (int i = 0; i < n; ++i)ans[indices[i]] = s[i];
return ans;
}
};
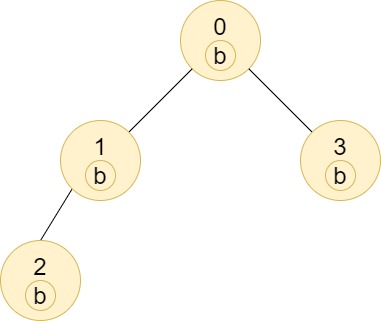
Given a tree (i.e. a connected, undirected graph that has no cycles) consisting of n nodes numbered from 0 to n - 1 and exactly n - 1edges. The root of the tree is the node 0, and each node of the tree has a label which is a lower-case character given in the string labels (i.e. The node with the number i has the label labels[i]).
The edges array is given on the form edges[i] = [ai, bi], which means there is an edge between nodes ai and bi in the tree.
Return an array of size n where ans[i] is the number of nodes in the subtree of the ith node which have the same label as node i.
A subtree of a tree T is the tree consisting of a node in T and all of its descendant nodes.
Example 1:
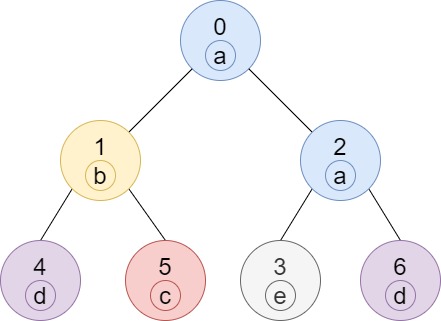
Input: n = 7, edges = [[0,1],[0,2],[1,4],[1,5],[2,3],[2,6]], labels = "abaedcd"
Output: [2,1,1,1,1,1,1]
Explanation: Node 0 has label 'a' and its sub-tree has node 2 with label 'a' as well, thus the answer is 2. Notice that any node is part of its sub-tree.
Node 1 has a label 'b'. The sub-tree of node 1 contains nodes 1,4 and 5, as nodes 4 and 5 have different labels than node 1, the answer is just 1 (the node itself).
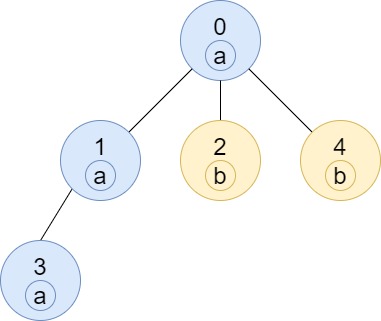
Example 2:
Input: n = 4, edges = [[0,1],[1,2],[0,3]], labels = "bbbb"
Output: [4,2,1,1]
Explanation: The sub-tree of node 2 contains only node 2, so the answer is 1.
The sub-tree of node 3 contains only node 3, so the answer is 1.
The sub-tree of node 1 contains nodes 1 and 2, both have label 'b', thus the answer is 2.
The sub-tree of node 0 contains nodes 0, 1, 2 and 3, all with label 'b', thus the answer is 4.
Given numBottles full water bottles, you can exchange numExchange empty water bottles for one full water bottle.
The operation of drinking a full water bottle turns it into an empty bottle.
Return the maximum number of water bottles you can drink.
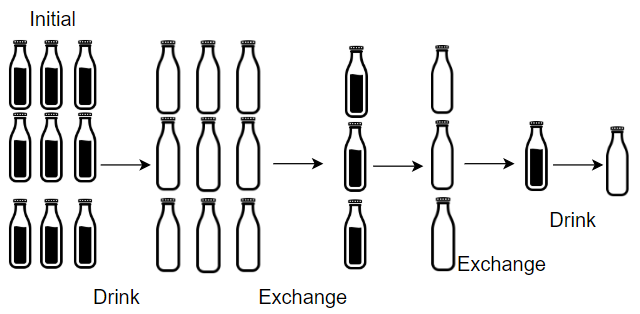
Example 1:
Input: numBottles = 9, numExchange = 3
Output: 13
Explanation: You can exchange 3 empty bottles to get 1 full water bottle.
Number of water bottles you can drink: 9 + 3 + 1 = 13.
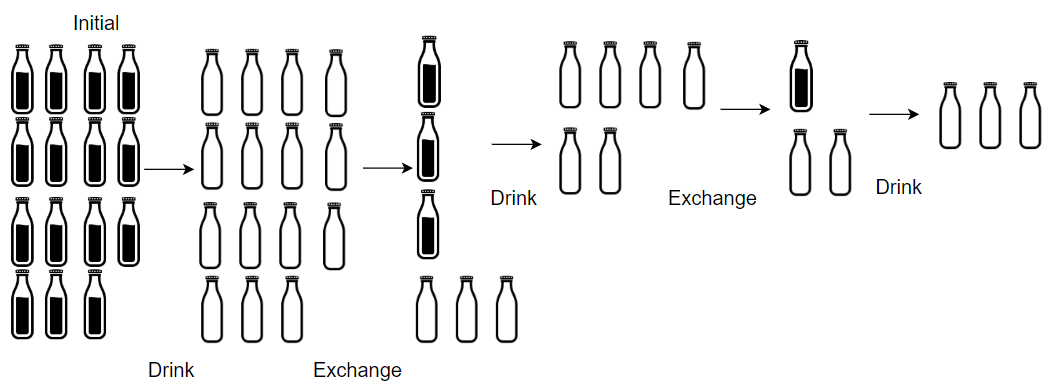
Example 2:
Input: numBottles = 15, numExchange = 4
Output: 19
Explanation: You can exchange 4 empty bottles to get 1 full water bottle.
Number of water bottles you can drink: 15 + 3 + 1 = 19.
class Solution {
public:
int numWaterBottles(int numBottles, int numExchange) {
int full = numBottles, empty = 0, div = numExchange;
int ans = 0;
while (full + empty >= div) {
ans += full;
empty += full;
full = empty / div;
empty = empty % div;
}
return ans + full;
}
};
const long long kMOD = 1e9 + 7;
class Solution {
long long CalAccSum(long long l) {
return (l %kMOD)* ((l + 1) % kMOD) / 2;
}
public:
int numSub(string s) {
long long ans = 0;
int i = 0, j = 0, n = s.size();
while (i < n) {
while (i < n&&s[i] == '0')++i;
if (i >= n)break;
j = i + 1;
while (j < n&&s[j] == '1')++j;
int m = j - i;
ans += CalAccSum(m) % kMOD;
i = j;
}
return ans % kMOD;
}
};
A pair (i,j) is called good if nums[i] == nums[j] and i < j.
Return the number of good pairs.
Example 1:
Input: nums = [1,2,3,1,1,3]
Output: 4
Explanation: There are 4 good pairs (0,3), (0,4), (3,4), (2,5) 0-indexed.
Example 2:
Input: nums = [1,1,1,1]
Output: 6
Explanation: Each pair in the array are good.
Example 3:
Input: nums = [1,2,3]
Output: 0
Constraints:
1 <= nums.length <= 100
1 <= nums[i] <= 100
直接按题意做就行:
class Solution {
public:
int numIdenticalPairs(vector<int>& nums) {
int ans = 0, n = nums.size();
for (int i = 0; i < n; ++i) {
for (int j = i + 1; j < n; ++j) {
if (nums[i] == nums[j])++ans;
}
}
return ans;
}
};
You are given an undirected weighted graph of n nodes (0-indexed), represented by an edge list where edges[i] = [a, b] is an undirected edge connecting the nodes a and b with a probability of success of traversing that edge succProb[i].
Given two nodes start and end, find the path with the maximum probability of success to go from start to end and return its success probability.
If there is no path from start to end, return 0. Your answer will be accepted if it differs from the correct answer by at most 1e-5.
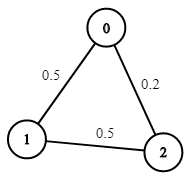
Example 1:
Input: n = 3, edges = [[0,1],[1,2],[0,2]], succProb = [0.5,0.5,0.2], start = 0, end = 2
Output: 0.25000
Explanation: There are two paths from start to end, one having a probability of success = 0.2 and the other has 0.5 * 0.5 = 0.25.
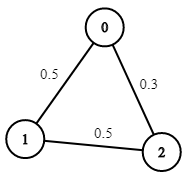
Example 2:
Input: n = 3, edges = [[0,1],[1,2],[0,2]], succProb = [0.5,0.5,0.3], start = 0, end = 2
Output: 0.30000
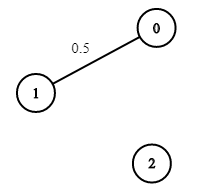
Example 3:
Input: n = 3, edges = [[0,1]], succProb = [0.5], start = 0, end = 2
Output: 0.00000
Explanation: There is no path between 0 and 2.
Constraints:
2 <= n <= 10^4
0 <= start, end < n
start != end
0 <= a, b < n
a != b
0 <= succProb.length == edges.length <= 2*10^4
0 <= succProb[i] <= 1
There is at most one edge between every two nodes.
给定一个无向图,边表示概率,问从start到end的最大概率是多少。
借此题复习一下若干最短路径算法吧。
首先朴素的DFS,代码如下:
class Solution {
private:
void DFS(const vector<vector<double>> &graph, vector<int> &visited, int start, int end, double curprob, double &maxprob) {
if (start == end) {
maxprob = max(maxprob, curprob);
return;
}
int n = graph.size();
for (int i = 0; i < n; ++i) {
if (visited[i] == 0 && graph[start][i] >= 0) {
visited[i] = 1;
DFS(graph, visited, i, end, curprob*graph[start][i], maxprob);
visited[i] = 0;
}
}
}
public:
double maxProbability(int n, vector<vector<int>>& edges, vector<double>& succProb, int start, int end) {
vector<vector<double>> graph(n, vector<double>(n, -1.0));
for (int i = 0; i < edges.size(); ++i) {
graph[edges[i][0]][edges[i][1]] = succProb[i];
graph[edges[i][1]][edges[i][0]] = succProb[i];
}
vector<int> visited(n, 0);
visited[start] = 1;
double maxprob = 0;
DFS(graph, visited, start, end, 1, maxprob);
return maxprob;
}
};