LeetCode Valid Square Given the coordinates of four points in 2D space, return whether the four points could construct a square. The coordinate (x,y) of a point is represented by an integer array with two integers. Example:
Input: p1 = [0,0], p2 = [1,1], p3 = [1,0], p4 = [0,1] Output: TrueNote:
- All the input integers are in the range [-10000, 10000].
- A valid square has four equal sides with positive length and four equal angles (90-degree angles).
- Input points have no order.
任给平面上的四个点,问这四个点能否构成正方形。 解法1,原始几何角度。 如果要构成正方形,必须满足四条边相等,且四个角是直角。因为给定的点的顺序是不固定的,假设我们固定一个点p1,求p1到其他三个点p2,p3,p4的距离的平方len2,len3,len4,则要形成正方形,这三个距离中必定有两个距离相等,且等于另一个距离的两倍。
p3------p4 | | | | p1------p2比如假设形成上述正方形,则有2*len2==2*len3==len4。在满足这个条件的基础上,还需要满足p1p2垂直p1p3,且p4p3垂直p4p2,且p4到p2和p3的距离相等。 当然因为点的顺序不固定,所以还有可能2*len2==2*len4==len3或者2*len3==2*len4==len2。最后需要注意的是这些点中不能由任何两个点重合,所以需要判断两点之间的距离不能为0。 完整代码如下: [cpp] class Solution2 { private: // 计算距离的平方 int distSquare(const vector<int>& p1, const vector<int>& p2) { return (p1[0] – p2[0])*(p1[0] – p2[0]) + (p1[1] – p2[1])*(p1[1] – p2[1]); } // 判断直线(p1,p2)和直线(p3,p4)是否垂直 bool isVertical(vector<int>& p1, vector<int>& p2, vector<int>& p3, vector<int>& p4) { return (p2[0] – p1[0])*(p4[0] – p3[0]) + (p2[1] – p1[1])*(p4[1] – p3[1]) == 0; } // 在2|p1p2|==2|p1p3|==|p1p4|的条件下,判断是否能形成正方形 bool helper(vector<int>& p1, vector<int>& p2, vector<int>& p3, vector<int>& p4) { if (!isVertical(p1, p2, p1, p3))return false; if (!isVertical(p4, p3, p4, p2))return false; int len2 = distSquare(p4, p2), len3 = distSquare(p4, p3); return len2 == len3; } public: bool validSquare(vector<int>& p1, vector<int>& p2, vector<int>& p3, vector<int>& p4) { int len2 = distSquare(p1, p2), len3 = distSquare(p1, p3), len4 = distSquare(p1, p4); if (len2 == 0 || len3 == 0 || len4 == 0)return false; if (len2 == len3 && 2 * len2 == len4) return helper(p1, p2, p3, p4); if (len2 == len4 && 2 * len2 == len3) return helper(p1, p2, p4, p3); if (len3 == len4 && 2 * len3 == len2) return helper(p1, p3, p4, p2); return false; } }; [/cpp] 本代码提交AC,用时6MS。 解法2,特征法。 任何一个正方形,如果求出所有点之间的距离,则这些距离只可能有两种取值,一种是邻边全相等,另一种是对角边也相等。所以我们只需要用一个map保存不同边的长度以及出现的频率即可,如果最终只有两个映射,则是正方形,否则不是。注意当出现边长为0时,说明两点重合,不能构成正方形。 代码如下: [cpp] class Solution { private: // 计算距离的平方 int distSquare(const vector<int>& p1, const vector<int>& p2) { return (p1[0] – p2[0])*(p1[0] – p2[0]) + (p1[1] – p2[1])*(p1[1] – p2[1]); } public: bool validSquare(vector<int>& p1, vector<int>& p2, vector<int>& p3, vector<int>& p4) { unordered_map<int, int> umdist; vector<vector<int>> points = { p1,p2,p3,p4 }; for (int i = 0; i < 4; ++i) { for (int j = i + 1; j < 4; ++j) { int dist = distSquare(points[i], points[j]); if (dist == 0)return false; ++umdist[dist]; } } return umdist.size() == 2; } }; [/cpp] 本代码提交AC,用时9MS。 不过上述代码有局限性,如果顶点都只是整数,则没有问题,但是如果顶点可以是实数,则会有问题。比如等边三角形的三个点和三角形的中心点,这四个点两两之间只有2种不同的距离,但他们不能构成正方形。可以再加一个限制条件,即两种不同长度的边的频率一个是4,一个是2,且出现2次的边长是出现4次的边长的两倍。 讨论区见:https://discuss.leetcode.com/topic/89985/c-3-lines-unordered_set/4]]>
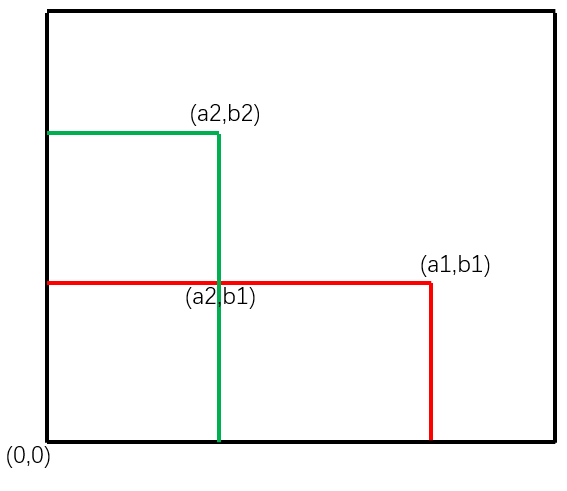 所以我们只需要遍历所有操作,分别找到行和列的最小值,则他们和原点围成的子矩阵的元素值最大,且相等。
代码非常简单,如下:
[cpp]
class Solution {
public:
int maxCount(int m, int n, vector<vector<int>>& ops) {
int minRow = m, minCol = n;
for (const auto &op : ops) {
minRow = min(minRow, op[0]);
minCol = min(minCol, op[1]);
}
return minRow*minCol;
}
};
[/cpp]
本代码提交AC,用时6MS。
]]>
所以我们只需要遍历所有操作,分别找到行和列的最小值,则他们和原点围成的子矩阵的元素值最大,且相等。
代码非常简单,如下:
[cpp]
class Solution {
public:
int maxCount(int m, int n, vector<vector<int>>& ops) {
int minRow = m, minCol = n;
for (const auto &op : ops) {
minRow = min(minRow, op[0]);
minCol = min(minCol, op[1]);
}
return minRow*minCol;
}
};
[/cpp]
本代码提交AC,用时6MS。
]]>