Given an array of integers, find out whether there are two distinct indices i and j in the array such that the absolute difference between nums[i] and nums[j] is at most t and the absolute difference between i and j is at most k.
Example 1:
Input: nums = [1,2,3,1], k = 3, t = 0
Output: true
Example 2:
Input: nums = [1,0,1,1], k = 1, t = 2
Output: true
Example 3:
Input: nums = [1,5,9,1,5,9], k = 2, t = 3 Output: false
typedef long long ll;
class Solution {
public:
bool containsNearbyAlmostDuplicate(vector<int>& nums, int k, int t)
{
set<ll> window;
for (int i = 0; i < nums.size(); ++i) {
if (i > k)
window.erase(nums[i – k – 1]); // 删除窗口左边的元素
auto it = window.lower_bound(ll(nums[i]) – t); // x>=nums[i]-t
if (it != window.end() && *it – nums[i] <= t)
return true; // x<=nums[i]+t
window.insert(nums[i]);
}
return false;
}
};
LeetCode Smallest Range
You have k lists of sorted integers in ascending order. Find the smallest range that includes at least one number from each of the k lists.
We define the range [a,b] is smaller than range [c language=",d"][/c] if b-a < d-c or a < c if b-a == d-c.
Example 1:
Input:[[4,10,15,24,26], [0,9,12,20], [5,18,22,30]]
Output: [20,24]
Explanation:
List 1: [4, 10, 15, 24,26], 24 is in range [20,24].
List 2: [0, 9, 12, 20], 20 is in range [20,24].
List 3: [5, 18, 22, 30], 22 is in range [20,24].
Note:
The given list may contain duplicates, so ascending order means >= here.
1 <= k <= 3500
-105 <= value of elements <= 105.
For Java users, please note that the input type has been changed to List<List<Integer>>. And after you reset the code template, you’ll see this point.
给定k个升序数组,求一个整数区间,该区间能至少包括所有数组的一个元素,且该区间最小。最小的定义是区间长度最小,如果区间长度相同,则区间起始点小则小。
参考Find smallest range containing elements from k lists这篇博客,突然发现GeeksforGeeks网站上的题比Leetcode上的多好多,而且都有详细题解和代码,好棒。
要求区间最小,则区间只包括每个数组的一个元素最好,所以我们要找k个数组中的k个数,使得这k个数的最大值和最小值的差最小,那么这个区间的两个端点就是这个最大值和最小值。
所以我们对k个数组维护k个指针,初始时都指向每个数组的首元素,然后找到这k个数的最大值和最小值,得到一个区间及其长度。然后我们不断循环:向前移动k个指针中的最小者,在新的k个数中求最大值和最小值及其区间长度。直到某个数组遍历结束,则返回得到的最小区间。
以样例为例。
LeetCode Find the Derangement of An Array
In combinatorial mathematics, a derangement is a permutation of the elements of a set, such that no element appears in its original position.
There’s originally an array consisting of n integers from 1 to n in ascending order, you need to find the number of derangement it can generate.
Also, since the answer may be very large, you should return the output mod 109 + 7.
Example 1:
Input: 3
Output: 2
Explanation: The original array is [1,2,3]. The two derangements are [2,3,1] and [3,1,2].
Note:n is in the range of [1, 106].
给定一个长度为n的数组[1,2,3,…,n],如果该数组的一个排列中,每个数字都不在它原来的位置了,我们称这个排列是原数组的一个Derangement(错排)。问长度为n的数组,有多少个Derangement。
维基百科关于错排问题有比较详细的解释。
假设dp[n]表示长度为n的数组的错排个数,显然dp[0]=1,dp[1]=0,dp[2]=1。如果已经知道dp[0,…,n-1],怎样求dp[n]。考虑第n个数,因为错排,它肯定不能放在第n位,假设n放在第k位,则有如下两种情况:
数字k放在了第n位,这时,相当于n和k交换了一下位置,还剩下n-2个数需要错排,所以+dp[n-2]
数字k不放在第n位,此时,可以理解为k原本的位置是n,也就是1不能放在第1位、2不能放在第2位、…、k不能放在第n位,也就相当于对n-1个数进行错排,所以+dp[n-1]
因为n可以放在1~n-1这n-1个位置,所以总的情况数等于dp[n]=(n-1)(dp[n-1]+dp[n-2])。
这就类似于求斐波那契数列的第n项了,维护前两个变量,不断滚动赋值就好了,时间复杂度O(n),代码如下:
[cpp]
const int MOD = 1000000007;
class Solution {
public:
int findDerangement(int n) {
if (n == 0)return 1;
if (n == 1)return 0;
long long p = 0, pp = 1;
for (int i = 2; i <= n; ++i) {
long long cur = ((i – 1)*(p + pp)) % MOD;
pp = p;
p = cur;
}
return p;
}
};
[/cpp]
本代码提交AC,用时13MS。]]>
LeetCode Design Log Storage System
You are given several logs that each log contains a unique id and timestamp. Timestamp is a string that has the following format: Year:Month:Day:Hour:Minute:Second, for example, 2017:01:01:23:59:59. All domains are zero-padded decimal numbers.
Design a log storage system to implement the following functions:
void Put(int id, string timestamp): Given a log’s unique id and timestamp, store the log in your storage system.
int[] Retrieve(String start, String end, String granularity): Return the id of logs whose timestamps are within the range from start to end. Start and end all have the same format as timestamp. However, granularity means the time level for consideration. For example, start = “2017:01:01:23:59:59”, end = “2017:01:02:23:59:59”, granularity = “Day”, it means that we need to find the logs within the range from Jan. 1st 2017 to Jan. 2nd 2017.
Example 1:
put(1, "2017:01:01:23:59:59");
put(2, "2017:01:01:22:59:59");
put(3, "2016:01:01:00:00:00");
retrieve("2016:01:01:01:01:01","2017:01:01:23:00:00","Year"); // return [1,2,3], because you need to return all logs within 2016 and 2017.
retrieve("2016:01:01:01:01:01","2017:01:01:23:00:00","Hour"); // return [1,2], because you need to return all logs start from 2016:01:01:01 to 2017:01:01:23, where log 3 is left outside the range.
Note:
There will be at most 300 operations of Put or Retrieve.
Year ranges from [2000,2017]. Hour ranges from [00,23].
LeetCode Sum of Square Numbers
Given a non-negative integer c, your task is to decide whether there’re two integers a and b such that a2 + b2 = c.
Example 1:
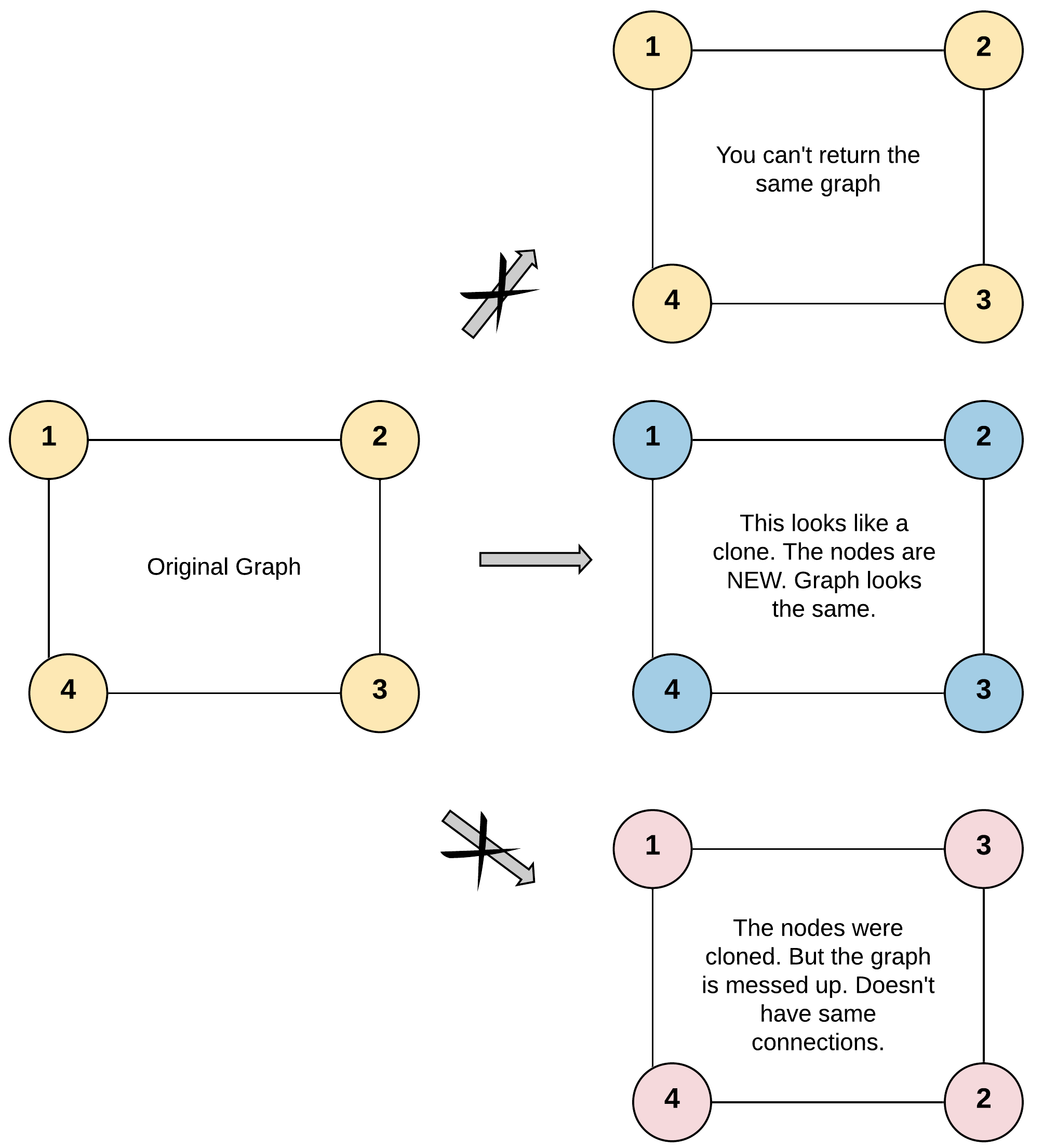
Each node in the graph contains a val (int) and a list (List[Node]) of its neighbors.
class Node {
public int val;
public List<Node> neighbors;
}
Test case format:
For simplicity sake, each node’s value is the same as the node’s index (1-indexed). For example, the first node with val = 1, the second node with val = 2, and so on. The graph is represented in the test case using an adjacency list.
Adjacency list is a collection of unordered lists used to represent a finite graph. Each list describes the set of neighbors of a node in the graph.
The given node will always be the first node with val = 1. You must return the copy of the given node as a reference to the cloned graph.
Example 1:
Input: adjList = [[2,4],[1,3],[2,4],[1,3]]
Output: [[2,4],[1,3],[2,4],[1,3]]
Explanation: There are 4 nodes in the graph.
1st node (val = 1)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
2nd node (val = 2)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
3rd node (val = 3)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
4th node (val = 4)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
Example 2:
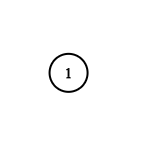
Input: adjList = [[]]
Output: [[]]
Explanation: Note that the input contains one empty list. The graph consists of only one node with val = 1 and it does not have any neighbors.
Example 3:
Input: adjList = []
Output: []
Explanation: This an empty graph, it does not have any nodes.
Example 4:
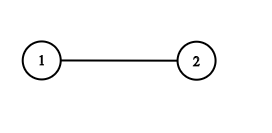
Input: adjList = [[2],[1]]
Output: [[2],[1]]
Constraints:
1 <= Node.val <= 100
Node.val is unique for each node.
Number of Nodes will not exceed 100.
There is no repeated edges and no self-loops in the graph.
The Graph is connected and all nodes can be visited starting from the given node.
Given a 2D board containing 'X' and 'O' (the letter O), capture all regions surrounded by 'X'.
A region is captured by flipping all 'O's into 'X's in that surrounded region.
Example:
X X X X
X O O X
X X O X
X O X X
After running your function, the board should be:
X X X X
X X X X
X X X X
X O X X
Explanation:
Surrounded regions shouldn’t be on the border, which means that any 'O' on the border of the board are not flipped to 'X'. Any 'O' that is not on the border and it is not connected to an 'O' on the border will be flipped to 'X'. Two cells are connected if they are adjacent cells connected horizontally or vertically.
vector<vector<int> > dirs = { { 1, 0 }, { -1, 0 }, { 0, 1 }, { 0, -1 } };
class Solution {
private:
int m, n;
bool isOk(int x, int y) { return x >= 0 && x < m && y >= 0 && y < n; }
void dfs(vector<vector<char> >& board, int x, int y)
{
board[x][y] = ‘1’;
for (int i = 0; i < dirs.size(); ++i) {
int u = x + dirs[i][0], v = y + dirs[i][1];
if (isOk(u, v) && board[u][v] == ‘O’)
dfs(board, u, v);
}
}
public:
void solve(vector<vector<char> >& board)
{
if (board.empty() || board[0].empty())
return;
m = board.size(), n = board[0].size();
for (int i = 0; i < m; ++i) {
if (board[i][0] == ‘O’)
dfs(board, i, 0);
if (board[i][n – 1] == ‘O’)
dfs(board, i, n – 1);
}
for (int j = 0; j < n; ++j) {
if (board[0][j] == ‘O’)
dfs(board, 0, j);
if (board[m – 1][j] == ‘O’)
dfs(board, m – 1, j);
}
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (board[i][j] == ‘O’)
board[i][j] = ‘X’;
else if (board[i][j] == ‘1’)
board[i][j] = ‘O’;
}
}
}
};
LeetCode Validate IP Address
Write a function to check whether an input string is a valid IPv4 address or IPv6 address or neither.
IPv4 addresses are canonically represented in dot-decimal notation, which consists of four decimal numbers, each ranging from 0 to 255, separated by dots (“.”), e.g.,172.16.254.1;
Besides, leading zeros in the IPv4 is invalid. For example, the address 172.16.254.01 is invalid.
IPv6 addresses are represented as eight groups of four hexadecimal digits, each group representing 16 bits. The groups are separated by colons (“:”). For example, the address 2001:0db8:85a3:0000:0000:8a2e:0370:7334 is a valid one. Also, we could omit some leading zeros among four hexadecimal digits and some low-case characters in the address to upper-case ones, so 2001:db8:85a3:0:0:8A2E:0370:7334 is also a valid IPv6 address(Omit leading zeros and using upper cases).
However, we don’t replace a consecutive group of zero value with a single empty group using two consecutive colons (::) to pursue simplicity. For example, 2001:0db8:85a3::8A2E:0370:7334 is an invalid IPv6 address.
Besides, extra leading zeros in the IPv6 is also invalid. For example, the address 02001:0db8:85a3:0000:0000:8a2e:0370:7334 is invalid.
Note: You may assume there is no extra space or special characters in the input string.
Example 1:
Input: "172.16.254.1"
Output: "IPv4"
Explanation: This is a valid IPv4 address, return "IPv4".
Example 2:
Input: "2001:0db8:85a3:0:0:8A2E:0370:7334"
Output: "IPv6"
Explanation: This is a valid IPv6 address, return "IPv6".
Example 3:
Input: "256.256.256.256"
Output: "Neither"
Explanation: This is neither a IPv4 address nor a IPv6 address.
LeetCode Wiggle Sort II
Given an unsorted array nums, reorder it such that nums[0] < nums[1] > nums[2] < nums[3]....
Example:
(1) Given nums = [1, 5, 1, 1, 6, 4], one possible answer is [1, 4, 1, 5, 1, 6].
(2) Given nums = [1, 3, 2, 2, 3, 1], one possible answer is [2, 3, 1, 3, 1, 2].
Note:
You may assume all input has valid answer.
Follow Up:
Can you do it in O(n) time and/or in-place with O(1) extra space?
给定一个数组,对其进行wiggle排序,如果下标从0开始,则奇数下标的数都要大于其相邻两个数,即nums[0] < nums[1] > nums[2] < nums[3]….
普通解法是这样的,先给数组排序,然后设置首尾指针,分别取较小的数放到偶数位,较大的数放到奇数位。比如第一个样例排序之后是[1,1,1,4,5,6],i指向1,j指向6,开辟一个新数组,依次把nums[i++]和nums[j–]放到新数组中,形成[1,6,1,5,1,4],满足要求。
但是有一种情况会出问题,比如[4,5,5,6],按上面的方法,得到的数组是[4,6,5,5],最后的5,5不满足要求,究其原因,是因为随着i和j的推进,他们指向的数的差值越来越小,导致最后可能出现相等的情况。遇到这种情况,我们可以设置i从mid开始取,j从n-1开始取,这样i和j指向的数的差值始终是很大的,这样得到的结果就是[5,6,4,5]
因为题目说每个样例都有解,而wiggle sort的结果是先小后大,所以小数的个数总是大于等于大数的个数,比如1,2,1小数的个数大于大数的个数,1,2,1,2小数的个数等于大数的个数。所以我们i从mid开始时,如果数组有偶数个数,则中位数有两个,我们的mid应该是前一个中位数,这样能保证小数个数等于大数个数;如果数组有奇数个数,则中位数只有一个,我们的mid就从这个中位数开始,这样小数个数比大数个数多1。
所以第一个版本我们可以
[cpp]
class Solution {
private:
//自己实现的快排程序
void my_quick_sort(vector<int>& nums, int s, int t) {
int i = s, j = t, pivot = s;
if (i >= j)return;
while (i <= j) {
while (i <= j&&nums[i] <= nums[pivot])++i;
if (i > j)break;
while (i <= j&&nums[j] >= nums[pivot])–j;
if (i > j)break;
swap(nums[i++], nums[j–]);
}
swap(nums[pivot], nums[j]);
my_quick_sort(nums, s, j – 1);
my_quick_sort(nums, j + 1, t);
}
public:
void wiggleSort(vector<int>& nums) {
int n = nums.size();
my_quick_sort(nums, 0, n – 1);
int i = (n & 1) == 0 ? n / 2 – 1 : n / 2, j = n – 1;
vector<int> ans(n, 0);
for (int k = 0; k < n; ++k) {
ans[k] = (k & 1) == 0 ? nums[i–] : nums[j–];
}
nums = ans;
}
};
[/cpp]
手工写了快排程序,并手工根据n的奇偶性对i赋不同的值。本代码提交AC,用时569MS。自己写的快排是有多慢呀。
我们也可以这样
[cpp]
class Solution {
public:
void wiggleSort(vector<int>& nums) {
sort(nums.begin(), nums.end());
int n = nums.size(), i = (n + 1) / 2, j = n;
vector<int> ans(n, 0);
for (int k = 0; k < n; ++k) {
ans[k] = (k & 1) == 0 ? nums[–i] : nums[–j];
}
nums = ans;
}
};
[/cpp]
使用库中的sort,并且(n+1)/2相当于得到了偶数长的较大的中位数,或者奇数长中位数的下一个数,为了校准,进行了–i处理。本代码提交AC,用时86MS。
讨论区还有O(n)时间O(1)空间的解法,下回再战。]]>
LeetCode Remove K Digits
Given a non-negative integer num represented as a string, remove k digits from the number so that the new number is the smallest possible.
Note:
The length of num is less than 10002 and will be ≥ k.
The given num does not contain any leading zero.
Example 1:
Input: num = "1432219", k = 3
Output: "1219"
Explanation: Remove the three digits 4, 3, and 2 to form the new number 1219 which is the smallest.
Example 2:
Input: num = "10200", k = 1
Output: "200"
Explanation: Remove the leading 1 and the number is 200. Note that the output must not contain leading zeroes.
Example 3:
Input: num = "10", k = 2
Output: "0"
Explanation: Remove all the digits from the number and it is left with nothing which is 0.
给定一个数字字符串,要求从中删除k个数字,使得最终结果最小,返回最小的数字字符串。
使用栈和贪心的思路。为了使结果尽量小,我们从左往右扫描字符串,把字符存到一个栈中,如果当前字符比栈顶小,则可以把栈顶数字删掉,这样相当于用当前字符代替栈顶字符所在位置,使得结果更小了。否则把当前字符压栈,注意此时不能把当前字符删掉,因为可能后面还有更大的字符出现。
如果这样过了一遍之后,还是没删够k个字符,此时,字符串从左往右肯定是非降序的。所以我们依次弹栈,把栈顶的元素删掉,直到删够k个字符。
最后还要判断一下剩余字符串是否为空,并删除前导零。完整代码如下:
[cpp]
class Solution {
public:
string removeKdigits(string num, int k) {
if (k >= num.size())return "0";
string ans = "";
for (const auto& c : num) {
if (ans.empty() || k == 0)ans.push_back(c);
else {
while (!ans.empty() && ans.back() > c) {
ans.pop_back();
if (–k == 0)break;
}
ans.push_back(c);
}
}
while (k– > 0 && !ans.empty()) ans.pop_back();
while (!ans.empty() && ans[0] == ‘0’)ans.erase(ans.begin());
return ans.empty() ? "0" : ans;
}
};
[/cpp]
本代码提交AC,用时6MS。]]>