LeetCode Sum of Square Numbers
Given a non-negative integer c, your task is to decide whether there’re two integers a and b such that a2 + b2 = c.
Example 1:
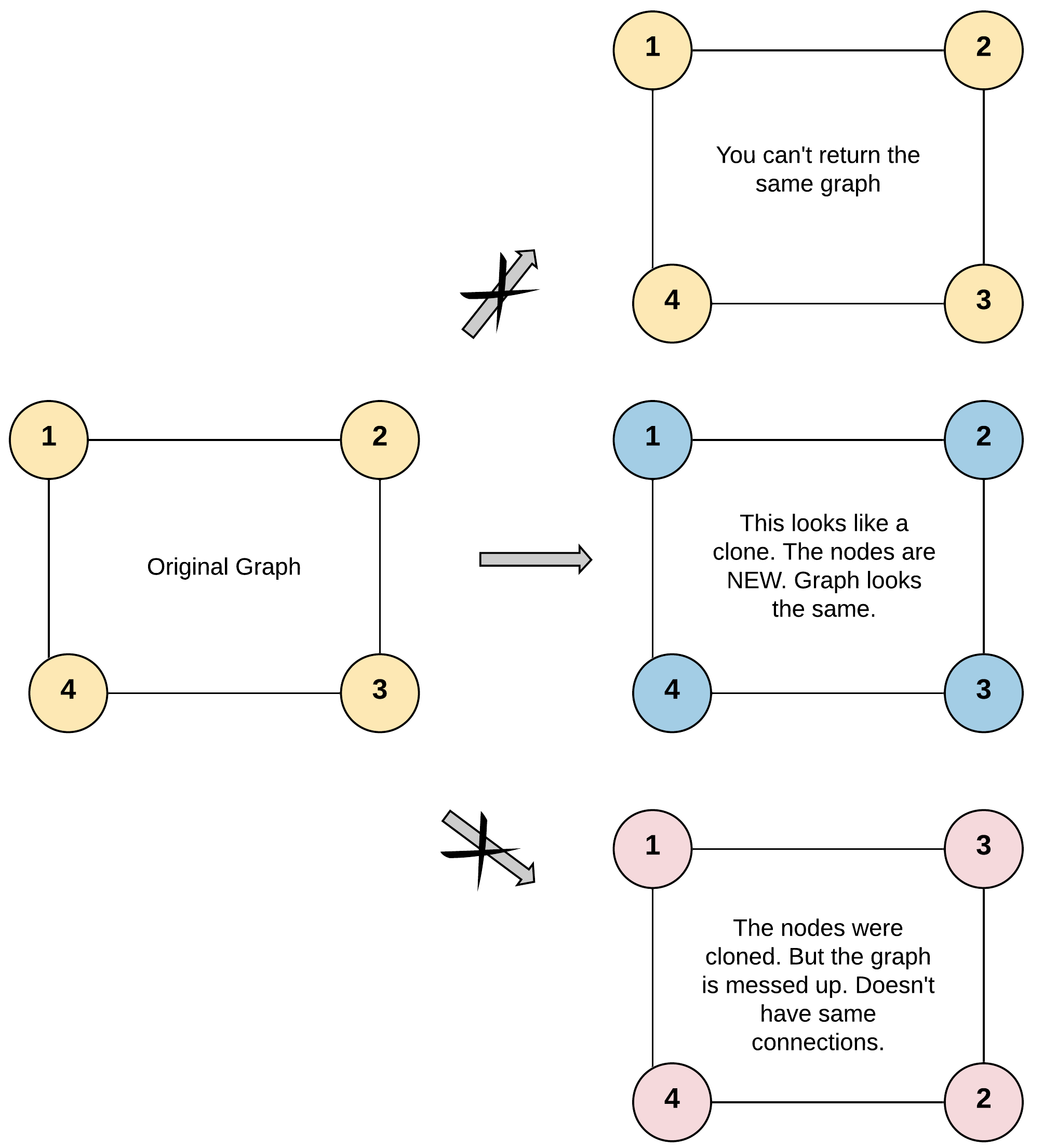
Each node in the graph contains a val (int) and a list (List[Node]) of its neighbors.
class Node {
public int val;
public List<Node> neighbors;
}
Test case format:
For simplicity sake, each node’s value is the same as the node’s index (1-indexed). For example, the first node with val = 1, the second node with val = 2, and so on. The graph is represented in the test case using an adjacency list.
Adjacency list is a collection of unordered lists used to represent a finite graph. Each list describes the set of neighbors of a node in the graph.
The given node will always be the first node with val = 1. You must return the copy of the given node as a reference to the cloned graph.
Example 1:
Input: adjList = [[2,4],[1,3],[2,4],[1,3]]
Output: [[2,4],[1,3],[2,4],[1,3]]
Explanation: There are 4 nodes in the graph.
1st node (val = 1)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
2nd node (val = 2)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
3rd node (val = 3)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
4th node (val = 4)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
Example 2:
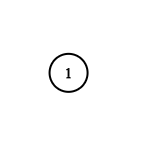
Input: adjList = [[]]
Output: [[]]
Explanation: Note that the input contains one empty list. The graph consists of only one node with val = 1 and it does not have any neighbors.
Example 3:
Input: adjList = []
Output: []
Explanation: This an empty graph, it does not have any nodes.
Example 4:
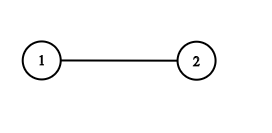
Input: adjList = [[2],[1]]
Output: [[2],[1]]
Constraints:
1 <= Node.val <= 100
Node.val is unique for each node.
Number of Nodes will not exceed 100.
There is no repeated edges and no self-loops in the graph.
The Graph is connected and all nodes can be visited starting from the given node.
Given a 2D board containing 'X' and 'O' (the letter O), capture all regions surrounded by 'X'.
A region is captured by flipping all 'O's into 'X's in that surrounded region.
Example:
X X X X
X O O X
X X O X
X O X X
After running your function, the board should be:
X X X X
X X X X
X X X X
X O X X
Explanation:
Surrounded regions shouldn’t be on the border, which means that any 'O' on the border of the board are not flipped to 'X'. Any 'O' that is not on the border and it is not connected to an 'O' on the border will be flipped to 'X'. Two cells are connected if they are adjacent cells connected horizontally or vertically.
vector<vector<int> > dirs = { { 1, 0 }, { -1, 0 }, { 0, 1 }, { 0, -1 } };
class Solution {
private:
int m, n;
bool isOk(int x, int y) { return x >= 0 && x < m && y >= 0 && y < n; }
void dfs(vector<vector<char> >& board, int x, int y)
{
board[x][y] = ‘1’;
for (int i = 0; i < dirs.size(); ++i) {
int u = x + dirs[i][0], v = y + dirs[i][1];
if (isOk(u, v) && board[u][v] == ‘O’)
dfs(board, u, v);
}
}
public:
void solve(vector<vector<char> >& board)
{
if (board.empty() || board[0].empty())
return;
m = board.size(), n = board[0].size();
for (int i = 0; i < m; ++i) {
if (board[i][0] == ‘O’)
dfs(board, i, 0);
if (board[i][n – 1] == ‘O’)
dfs(board, i, n – 1);
}
for (int j = 0; j < n; ++j) {
if (board[0][j] == ‘O’)
dfs(board, 0, j);
if (board[m – 1][j] == ‘O’)
dfs(board, m – 1, j);
}
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (board[i][j] == ‘O’)
board[i][j] = ‘X’;
else if (board[i][j] == ‘1’)
board[i][j] = ‘O’;
}
}
}
};
LeetCode Validate IP Address
Write a function to check whether an input string is a valid IPv4 address or IPv6 address or neither.
IPv4 addresses are canonically represented in dot-decimal notation, which consists of four decimal numbers, each ranging from 0 to 255, separated by dots (“.”), e.g.,172.16.254.1;
Besides, leading zeros in the IPv4 is invalid. For example, the address 172.16.254.01 is invalid.
IPv6 addresses are represented as eight groups of four hexadecimal digits, each group representing 16 bits. The groups are separated by colons (“:”). For example, the address 2001:0db8:85a3:0000:0000:8a2e:0370:7334 is a valid one. Also, we could omit some leading zeros among four hexadecimal digits and some low-case characters in the address to upper-case ones, so 2001:db8:85a3:0:0:8A2E:0370:7334 is also a valid IPv6 address(Omit leading zeros and using upper cases).
However, we don’t replace a consecutive group of zero value with a single empty group using two consecutive colons (::) to pursue simplicity. For example, 2001:0db8:85a3::8A2E:0370:7334 is an invalid IPv6 address.
Besides, extra leading zeros in the IPv6 is also invalid. For example, the address 02001:0db8:85a3:0000:0000:8a2e:0370:7334 is invalid.
Note: You may assume there is no extra space or special characters in the input string.
Example 1:
Input: "172.16.254.1"
Output: "IPv4"
Explanation: This is a valid IPv4 address, return "IPv4".
Example 2:
Input: "2001:0db8:85a3:0:0:8A2E:0370:7334"
Output: "IPv6"
Explanation: This is a valid IPv6 address, return "IPv6".
Example 3:
Input: "256.256.256.256"
Output: "Neither"
Explanation: This is neither a IPv4 address nor a IPv6 address.
LeetCode Wiggle Sort II
Given an unsorted array nums, reorder it such that nums[0] < nums[1] > nums[2] < nums[3]....
Example:
(1) Given nums = [1, 5, 1, 1, 6, 4], one possible answer is [1, 4, 1, 5, 1, 6].
(2) Given nums = [1, 3, 2, 2, 3, 1], one possible answer is [2, 3, 1, 3, 1, 2].
Note:
You may assume all input has valid answer.
Follow Up:
Can you do it in O(n) time and/or in-place with O(1) extra space?
给定一个数组,对其进行wiggle排序,如果下标从0开始,则奇数下标的数都要大于其相邻两个数,即nums[0] < nums[1] > nums[2] < nums[3]….
普通解法是这样的,先给数组排序,然后设置首尾指针,分别取较小的数放到偶数位,较大的数放到奇数位。比如第一个样例排序之后是[1,1,1,4,5,6],i指向1,j指向6,开辟一个新数组,依次把nums[i++]和nums[j–]放到新数组中,形成[1,6,1,5,1,4],满足要求。
但是有一种情况会出问题,比如[4,5,5,6],按上面的方法,得到的数组是[4,6,5,5],最后的5,5不满足要求,究其原因,是因为随着i和j的推进,他们指向的数的差值越来越小,导致最后可能出现相等的情况。遇到这种情况,我们可以设置i从mid开始取,j从n-1开始取,这样i和j指向的数的差值始终是很大的,这样得到的结果就是[5,6,4,5]
因为题目说每个样例都有解,而wiggle sort的结果是先小后大,所以小数的个数总是大于等于大数的个数,比如1,2,1小数的个数大于大数的个数,1,2,1,2小数的个数等于大数的个数。所以我们i从mid开始时,如果数组有偶数个数,则中位数有两个,我们的mid应该是前一个中位数,这样能保证小数个数等于大数个数;如果数组有奇数个数,则中位数只有一个,我们的mid就从这个中位数开始,这样小数个数比大数个数多1。
所以第一个版本我们可以
[cpp]
class Solution {
private:
//自己实现的快排程序
void my_quick_sort(vector<int>& nums, int s, int t) {
int i = s, j = t, pivot = s;
if (i >= j)return;
while (i <= j) {
while (i <= j&&nums[i] <= nums[pivot])++i;
if (i > j)break;
while (i <= j&&nums[j] >= nums[pivot])–j;
if (i > j)break;
swap(nums[i++], nums[j–]);
}
swap(nums[pivot], nums[j]);
my_quick_sort(nums, s, j – 1);
my_quick_sort(nums, j + 1, t);
}
public:
void wiggleSort(vector<int>& nums) {
int n = nums.size();
my_quick_sort(nums, 0, n – 1);
int i = (n & 1) == 0 ? n / 2 – 1 : n / 2, j = n – 1;
vector<int> ans(n, 0);
for (int k = 0; k < n; ++k) {
ans[k] = (k & 1) == 0 ? nums[i–] : nums[j–];
}
nums = ans;
}
};
[/cpp]
手工写了快排程序,并手工根据n的奇偶性对i赋不同的值。本代码提交AC,用时569MS。自己写的快排是有多慢呀。
我们也可以这样
[cpp]
class Solution {
public:
void wiggleSort(vector<int>& nums) {
sort(nums.begin(), nums.end());
int n = nums.size(), i = (n + 1) / 2, j = n;
vector<int> ans(n, 0);
for (int k = 0; k < n; ++k) {
ans[k] = (k & 1) == 0 ? nums[–i] : nums[–j];
}
nums = ans;
}
};
[/cpp]
使用库中的sort,并且(n+1)/2相当于得到了偶数长的较大的中位数,或者奇数长中位数的下一个数,为了校准,进行了–i处理。本代码提交AC,用时86MS。
讨论区还有O(n)时间O(1)空间的解法,下回再战。]]>
LeetCode Remove K Digits
Given a non-negative integer num represented as a string, remove k digits from the number so that the new number is the smallest possible.
Note:
The length of num is less than 10002 and will be ≥ k.
The given num does not contain any leading zero.
Example 1:
Input: num = "1432219", k = 3
Output: "1219"
Explanation: Remove the three digits 4, 3, and 2 to form the new number 1219 which is the smallest.
Example 2:
Input: num = "10200", k = 1
Output: "200"
Explanation: Remove the leading 1 and the number is 200. Note that the output must not contain leading zeroes.
Example 3:
Input: num = "10", k = 2
Output: "0"
Explanation: Remove all the digits from the number and it is left with nothing which is 0.
给定一个数字字符串,要求从中删除k个数字,使得最终结果最小,返回最小的数字字符串。
使用栈和贪心的思路。为了使结果尽量小,我们从左往右扫描字符串,把字符存到一个栈中,如果当前字符比栈顶小,则可以把栈顶数字删掉,这样相当于用当前字符代替栈顶字符所在位置,使得结果更小了。否则把当前字符压栈,注意此时不能把当前字符删掉,因为可能后面还有更大的字符出现。
如果这样过了一遍之后,还是没删够k个字符,此时,字符串从左往右肯定是非降序的。所以我们依次弹栈,把栈顶的元素删掉,直到删够k个字符。
最后还要判断一下剩余字符串是否为空,并删除前导零。完整代码如下:
[cpp]
class Solution {
public:
string removeKdigits(string num, int k) {
if (k >= num.size())return "0";
string ans = "";
for (const auto& c : num) {
if (ans.empty() || k == 0)ans.push_back(c);
else {
while (!ans.empty() && ans.back() > c) {
ans.pop_back();
if (–k == 0)break;
}
ans.push_back(c);
}
}
while (k– > 0 && !ans.empty()) ans.pop_back();
while (!ans.empty() && ans[0] == ‘0’)ans.erase(ans.begin());
return ans.empty() ? "0" : ans;
}
};
[/cpp]
本代码提交AC,用时6MS。]]>
const int MAXN = 26;
class Trie {
private:
struct Node {
char c;
bool isWord;
Node(char c_, bool isWord_)
: c(c_)
, isWord(isWord_)
{
for (int i = 0; i < MAXN; ++i)
children.push_back(NULL);
};
vector<Node*> children;
};
Node* root;
public: /** Initialize your data structure here. */
Trie() { root = new Node(‘ ‘, true); } /** Inserts a word into the trie. */
void insert(string word)
{
Node* cur = root;
for (int i = 0; i < word.size(); ++i) {
int idx = word[i] – ‘a’;
if (cur->children[idx] == NULL)
cur->children[idx] = new Node(word[i], false);
cur = cur->children[idx];
}
cur->isWord = true;
} /** Returns if the word is in the trie. */
bool search(string word)
{
Node* cur = root;
for (int i = 0; i < word.size(); ++i) {
int idx = word[i] – ‘a’;
if (cur->children[idx] == NULL)
return false;
cur = cur->children[idx];
}
return cur->isWord;
} /** Returns if there is any word in the trie that starts with the given prefix. */
bool startsWith(string prefix)
{
Node* cur = root;
for (int i = 0; i < prefix.size(); ++i) {
int idx = prefix[i] – ‘a’;
if (cur->children[idx] == NULL)
return false;
cur = cur->children[idx];
}
return true;
}
};
You are given coins of different denominations and a total amount of money amount. Write a function to compute the fewest number of coins that you need to make up that amount. If that amount of money cannot be made up by any combination of the coins, return -1.
There are a total of n courses you have to take, labeled from 0 to n-1.
Some courses may have prerequisites, for example to take course 0 you have to first take course 1, which is expressed as a pair: [0,1]
Given the total number of courses and a list of prerequisite pairs, return the ordering of courses you should take to finish all courses.
There may be multiple correct orders, you just need to return one of them. If it is impossible to finish all courses, return an empty array.
Example 1:
Input: 2, [[1,0]]
Output: [0,1]Explanation: There are a total of 2 courses to take. To take course 1 you should have finished
course 0. So the correct course order is [0,1] .
Example 2:
Input: 4, [[1,0],[2,0],[3,1],[3,2]]
Output: [0,1,2,3] or [0,2,1,3]Explanation: There are a total of 4 courses to take. To take course 3 you should have finished both
courses 1 and 2. Both courses 1 and 2 should be taken after you finished course 0.
So one correct course order is [0,1,2,3]. Another correct ordering is [0,2,1,3] .
Note:
The input prerequisites is a graph represented by a list of edges, not adjacency matrices. Read more about how a graph is represented.
You may assume that there are no duplicate edges in the input prerequisites.
LeetCode K-diff Pairs in an Array
Given an array of integers and an integer k, you need to find the number of unique k-diff pairs in the array. Here a k-diff pair is defined as an integer pair (i, j), where i and j are both numbers in the array and their absolute difference is k.
Example 1:
Input: [3, 1, 4, 1, 5], k = 2
Output: 2
Explanation: There are two 2-diff pairs in the array, (1, 3) and (3, 5).
Although we have two 1s in the input, we should only return the number of unique pairs.
Example 2:
Input:[1, 2, 3, 4, 5], k = 1
Output: 4
Explanation: There are four 1-diff pairs in the array, (1, 2), (2, 3), (3, 4) and (4, 5).
Example 3:
Input: [1, 3, 1, 5, 4], k = 0
Output: 1
Explanation: There is one 0-diff pair in the array, (1, 1).
Note:
The pairs (i, j) and (j, i) count as the same pair.
The length of the array won’t exceed 10,000.
All the integers in the given input belong to the range: [-1e7, 1e7].
给定一个数组,问数组中绝对差值为k的unique数对有多少个。
注意数对不能有重复,比如第一个样例,虽然有两个1,但是2-diff的数对(1,3)只能算一个。
我使用的方法非常简单直白。首先因为绝对误差肯定是非负数,所以如果k<0,则直接返回0对。
然后如果k==0,则说明数对中的两个数必须相等,所以对于k==0的情况,只需要统计一下数组中有多少个重复的数。
如果k>0,则对于每一个数num,如果num+k也在数组中,则找到一个k-diff的数对。
所以为了方便查找和统计,我们首先把数和频率统计到一个map中,边map,可以边统计重复数字个数repeated。
如果k==0,直接返回repeated。
否则把map的key放到一个新的vector中,根据map的性质,这个新的vector是sorted的。则遍历sorted数组,判断每个num+k是否在map中,在则++ans。最后返回ans。
完整代码如下:
[cpp]
class Solution {
public:
int findPairs(vector<int>& nums, int k) {
if (k < 0)return 0;
int repeated = 0;
map<int, int> count;
for (const auto& num : nums) {
++count[num];
if (count[num] == 2)++repeated;
}
if (k == 0)return repeated;
vector<int> sorted;
for (const auto& it : count) {
sorted.push_back(it.first);
}
int ans = 0;
for (const auto& num : sorted) {
if (count.find(num + k) != count.end())++ans;
}
return ans;
}
};
[/cpp]
本代码提交AC,用时48MS。]]>