Given a string s and an integer array indices of the same length.
The string s will be shuffled such that the character at the ith position moves to indices[i] in the shuffled string.
Return the shuffled string.
Example 1:
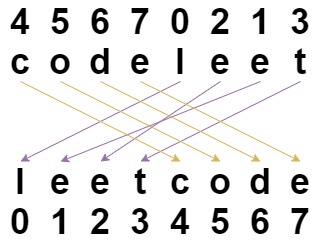
Input: s = "codeleet", indices = [4,5,6,7,0,2,1,3]
Output: "leetcode"
Explanation: As shown, "codeleet" becomes "leetcode" after shuffling.
Example 2:
Input: s = "abc", indices = [0,1,2]
Output: "abc"
Explanation: After shuffling, each character remains in its position.
Example 3:
Input: s = "aiohn", indices = [3,1,4,2,0]
Output: "nihao"
Example 4:
Input: s = "aaiougrt", indices = [4,0,2,6,7,3,1,5]
Output: "arigatou"
Example 5:
Input: s = "art", indices = [1,0,2]
Output: "rat"
Constraints:
s.length == indices.length == n
1 <= n <= 100
s contains only lower-case English letters.
0 <= indices[i] < n
All values of indices are unique (i.e. indices is a permutation of the integers from 0 to n - 1).
给定一个字符串,根据给定规则进行shuffle,直接照做。代码如下:
class Solution {
public:
string restoreString(string s, vector<int>& indices) {
int n = s.size();
string ans = s;
for (int i = 0; i < n; ++i)ans[indices[i]] = s[i];
return ans;
}
};
Given a tree (i.e. a connected, undirected graph that has no cycles) consisting of n nodes numbered from 0 to n - 1 and exactly n - 1edges. The root of the tree is the node 0, and each node of the tree has a label which is a lower-case character given in the string labels (i.e. The node with the number i has the label labels[i]).
The edges array is given on the form edges[i] = [ai, bi], which means there is an edge between nodes ai and bi in the tree.
Return an array of size n where ans[i] is the number of nodes in the subtree of the ith node which have the same label as node i.
A subtree of a tree T is the tree consisting of a node in T and all of its descendant nodes.
Example 1:
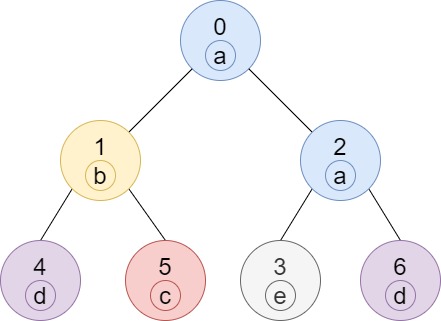
Input: n = 7, edges = [[0,1],[0,2],[1,4],[1,5],[2,3],[2,6]], labels = "abaedcd"
Output: [2,1,1,1,1,1,1]
Explanation: Node 0 has label 'a' and its sub-tree has node 2 with label 'a' as well, thus the answer is 2. Notice that any node is part of its sub-tree.
Node 1 has a label 'b'. The sub-tree of node 1 contains nodes 1,4 and 5, as nodes 4 and 5 have different labels than node 1, the answer is just 1 (the node itself).
Example 2:
Input: n = 4, edges = [[0,1],[1,2],[0,3]], labels = "bbbb"
Output: [4,2,1,1]
Explanation: The sub-tree of node 2 contains only node 2, so the answer is 1.
The sub-tree of node 3 contains only node 3, so the answer is 1.
The sub-tree of node 1 contains nodes 1 and 2, both have label 'b', thus the answer is 2.
The sub-tree of node 0 contains nodes 0, 1, 2 and 3, all with label 'b', thus the answer is 4.
Given numBottles full water bottles, you can exchange numExchange empty water bottles for one full water bottle.
The operation of drinking a full water bottle turns it into an empty bottle.
Return the maximum number of water bottles you can drink.
Example 1:
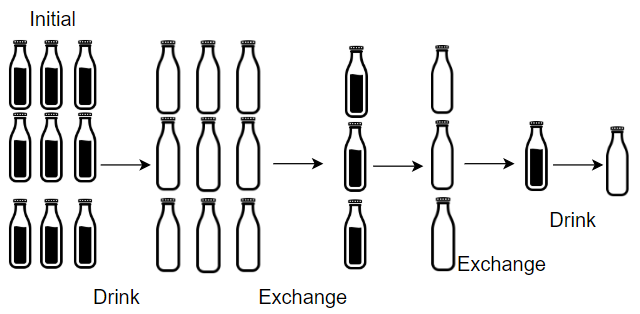
Input: numBottles = 9, numExchange = 3
Output: 13
Explanation: You can exchange 3 empty bottles to get 1 full water bottle.
Number of water bottles you can drink: 9 + 3 + 1 = 13.
Example 2:
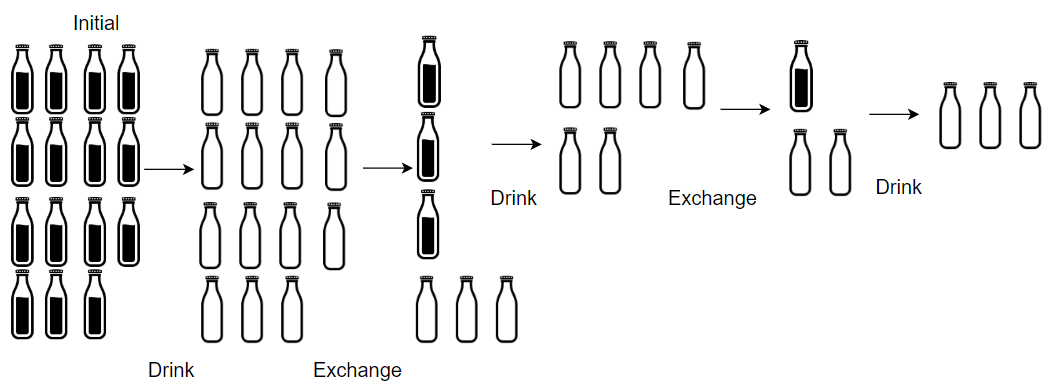
Input: numBottles = 15, numExchange = 4
Output: 19
Explanation: You can exchange 4 empty bottles to get 1 full water bottle.
Number of water bottles you can drink: 15 + 3 + 1 = 19.
class Solution {
public:
int numWaterBottles(int numBottles, int numExchange) {
int full = numBottles, empty = 0, div = numExchange;
int ans = 0;
while (full + empty >= div) {
ans += full;
empty += full;
full = empty / div;
empty = empty % div;
}
return ans + full;
}
};
const long long kMOD = 1e9 + 7;
class Solution {
long long CalAccSum(long long l) {
return (l %kMOD)* ((l + 1) % kMOD) / 2;
}
public:
int numSub(string s) {
long long ans = 0;
int i = 0, j = 0, n = s.size();
while (i < n) {
while (i < n&&s[i] == '0')++i;
if (i >= n)break;
j = i + 1;
while (j < n&&s[j] == '1')++j;
int m = j - i;
ans += CalAccSum(m) % kMOD;
i = j;
}
return ans % kMOD;
}
};
A pair (i,j) is called good if nums[i] == nums[j] and i < j.
Return the number of good pairs.
Example 1:
Input: nums = [1,2,3,1,1,3]
Output: 4
Explanation: There are 4 good pairs (0,3), (0,4), (3,4), (2,5) 0-indexed.
Example 2:
Input: nums = [1,1,1,1]
Output: 6
Explanation: Each pair in the array are good.
Example 3:
Input: nums = [1,2,3]
Output: 0
Constraints:
1 <= nums.length <= 100
1 <= nums[i] <= 100
直接按题意做就行:
class Solution {
public:
int numIdenticalPairs(vector<int>& nums) {
int ans = 0, n = nums.size();
for (int i = 0; i < n; ++i) {
for (int j = i + 1; j < n; ++j) {
if (nums[i] == nums[j])++ans;
}
}
return ans;
}
};
You are given an undirected weighted graph of n nodes (0-indexed), represented by an edge list where edges[i] = [a, b] is an undirected edge connecting the nodes a and b with a probability of success of traversing that edge succProb[i].
Given two nodes start and end, find the path with the maximum probability of success to go from start to end and return its success probability.
If there is no path from start to end, return 0. Your answer will be accepted if it differs from the correct answer by at most 1e-5.
Example 1:
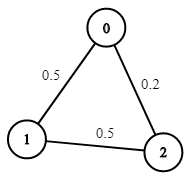
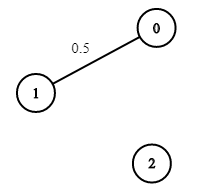
Input: n = 3, edges = [[0,1],[1,2],[0,2]], succProb = [0.5,0.5,0.2], start = 0, end = 2
Output: 0.25000
Explanation: There are two paths from start to end, one having a probability of success = 0.2 and the other has 0.5 * 0.5 = 0.25.
Example 2:
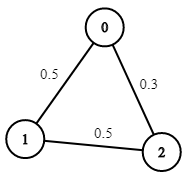
Input: n = 3, edges = [[0,1],[1,2],[0,2]], succProb = [0.5,0.5,0.3], start = 0, end = 2
Output: 0.30000
Example 3:
Input: n = 3, edges = [[0,1]], succProb = [0.5], start = 0, end = 2
Output: 0.00000
Explanation: There is no path between 0 and 2.
Constraints:
2 <= n <= 10^4
0 <= start, end < n
start != end
0 <= a, b < n
a != b
0 <= succProb.length == edges.length <= 2*10^4
0 <= succProb[i] <= 1
There is at most one edge between every two nodes.
给定一个无向图,边表示概率,问从start到end的最大概率是多少。
借此题复习一下若干最短路径算法吧。
首先朴素的DFS,代码如下:
class Solution {
private:
void DFS(const vector<vector<double>> &graph, vector<int> &visited, int start, int end, double curprob, double &maxprob) {
if (start == end) {
maxprob = max(maxprob, curprob);
return;
}
int n = graph.size();
for (int i = 0; i < n; ++i) {
if (visited[i] == 0 && graph[start][i] >= 0) {
visited[i] = 1;
DFS(graph, visited, i, end, curprob*graph[start][i], maxprob);
visited[i] = 0;
}
}
}
public:
double maxProbability(int n, vector<vector<int>>& edges, vector<double>& succProb, int start, int end) {
vector<vector<double>> graph(n, vector<double>(n, -1.0));
for (int i = 0; i < edges.size(); ++i) {
graph[edges[i][0]][edges[i][1]] = succProb[i];
graph[edges[i][1]][edges[i][0]] = succProb[i];
}
vector<int> visited(n, 0);
visited[start] = 1;
double maxprob = 0;
DFS(graph, visited, start, end, 1, maxprob);
return maxprob;
}
};
We have a wooden plank of the length nunits. Some ants are walking on the plank, each ant moves with speed 1 unit per second. Some of the ants move to the left, the other move to the right.
When two ants moving in two different directions meet at some point, they change their directions and continue moving again. Assume changing directions doesn’t take any additional time.
When an ant reaches one end of the plank at a time t, it falls out of the plank imediately.
Given an integer n and two integer arrays left and right, the positions of the ants moving to the left and the right. Return the moment when the last ant(s) fall out of the plank.
Example 1:
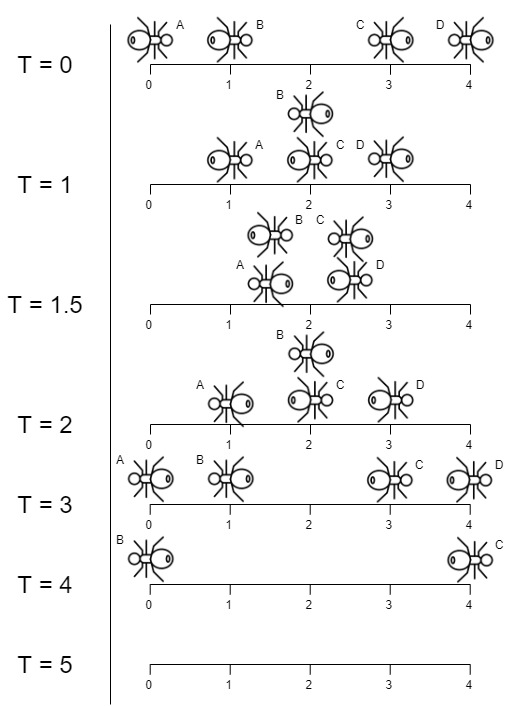
Input: n = 4, left = [4,3], right = [0,1]
Output: 4
Explanation: In the image above:
-The ant at index 0 is named A and going to the right.
-The ant at index 1 is named B and going to the right.
-The ant at index 3 is named C and going to the left.
-The ant at index 4 is named D and going to the left.
Note that the last moment when an ant was on the plank is t = 4 second, after that it falls imediately out of the plank. (i.e. We can say that at t = 4.0000000001, there is no ants on the plank).
Example 2:
Input: n = 7, left = [], right = [0,1,2,3,4,5,6,7]
Output: 7
Explanation: All ants are going to the right, the ant at index 0 needs 7 seconds to fall.
Example 3:
Input: n = 7, left = [0,1,2,3,4,5,6,7], right = []
Output: 7
Explanation: All ants are going to the left, the ant at index 7 needs 7 seconds to fall.
Example 4:
Input: n = 9, left = [5], right = [4]
Output: 5
Explanation: At t = 1 second, both ants will be at the same intial position but with different direction.
Example 5:
Input: n = 6, left = [6], right = [0]
Output: 6
Constraints:
1 <= n <= 10^4
0 <= left.length <= n + 1
0 <= left[i] <= n
0 <= right.length <= n + 1
0 <= right[i] <= n
1 <= left.length + right.length <= n + 1
All values of left and right are unique, and each value can appear only in one of the two arrays.
class Solution {
public:
int getLastMoment(int n, vector<int>& left, vector<int>& right) {
sort(left.begin(), left.end());
sort(right.begin(), right.end());
int ans = 0;
if (!left.empty())ans = max(ans, left.back());
if (!right.empty())ans = max(ans, n - right.front());
return ans;
}
};
Given an array of numbers arr. A sequence of numbers is called an arithmetic progression if the difference between any two consecutive elements is the same.
Return true if the array can be rearranged to form an arithmetic progression, otherwise, return false.
Example 1:
Input: arr = [3,5,1]
Output: true
Explanation: We can reorder the elements as [1,3,5] or [5,3,1] with differences 2 and -2 respectively, between each consecutive elements.
Example 2:
Input: arr = [1,2,4]
Output: false
Explanation: There is no way to reorder the elements to obtain an arithmetic progression.
Constraints:
2 <= arr.length <= 1000
-10^6 <= arr[i] <= 10^6
给一个数组,问能否通过排列组合让这个数组变成等差数列。
直接排序,看看是否是等差数列即可:
class Solution {
public:
bool canMakeArithmeticProgression(vector<int>& arr) {
sort(arr.begin(), arr.end());
int diff = arr[1] - arr[0];
for (int i = 2; i < arr.size(); ++i) {
if (arr[i] - arr[i - 1] != diff)return false;
}
return true;
}
};
Your country has an infinite number of lakes. Initially, all the lakes are empty, but when it rains over the nth lake, the nth lake becomes full of water. If it rains over a lake which is full of water, there will be a flood. Your goal is to avoid the flood in any lake.
Given an integer array rains where:
rains[i] > 0 means there will be rains over the rains[i] lake.
rains[i] == 0 means there are no rains this day and you can choose one lake this day and dry it.
Return an array ans where:
ans.length == rains.length
ans[i] == -1 if rains[i] > 0.
ans[i] is the lake you choose to dry in the ith day if rains[i] == 0.
If there are multiple valid answers return any of them. If it is impossible to avoid flood return an empty array.
Notice that if you chose to dry a full lake, it becomes empty, but if you chose to dry an empty lake, nothing changes. (see example 4)
Example 1:
Input: rains = [1,2,3,4]
Output: [-1,-1,-1,-1]
Explanation: After the first day full lakes are [1]
After the second day full lakes are [1,2]
After the third day full lakes are [1,2,3]
After the fourth day full lakes are [1,2,3,4]
There's no day to dry any lake and there is no flood in any lake.
Example 2:
Input: rains = [1,2,0,0,2,1]
Output: [-1,-1,2,1,-1,-1]
Explanation: After the first day full lakes are [1]
After the second day full lakes are [1,2]
After the third day, we dry lake 2. Full lakes are [1]
After the fourth day, we dry lake 1. There is no full lakes.
After the fifth day, full lakes are [2].
After the sixth day, full lakes are [1,2].
It is easy that this scenario is flood-free. [-1,-1,1,2,-1,-1] is another acceptable scenario.
Example 3:
Input: rains = [1,2,0,1,2]
Output: []
Explanation: After the second day, full lakes are [1,2]. We have to dry one lake in the third day.
After that, it will rain over lakes [1,2]. It's easy to prove that no matter which lake you choose to dry in the 3rd day, the other one will flood.
Example 4:
Input: rains = [69,0,0,0,69]
Output: [-1,69,1,1,-1]
Explanation: Any solution on one of the forms [-1,69,x,y,-1], [-1,x,69,y,-1] or [-1,x,y,69,-1] is acceptable where 1 <= x,y <= 10^9
Example 5:
Input: rains = [10,20,20]
Output: []
Explanation: It will rain over lake 20 two consecutive days. There is no chance to dry any lake.