hihoCoder 1069-最近公共祖先·三 #1069 : 最近公共祖先·三 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 上上回说到,小Hi和小Ho使用了Tarjan算法来优化了他们的“最近公共祖先”网站,但是很快这样一个离线算法就出现了问题:如果只有一个人提出了询问,那么小Hi和小Ho很难决定到底是针对这个询问就直接进行计算还是等待一定数量的询问一起计算。毕竟无论是一个询问还是很多个询问,使用离线算法都是只需要做一次深度优先搜索就可以了的。 那么问题就来了,如果每次计算都只针对一个询问进行的话,那么这样的算法事实上还不如使用最开始的朴素算法呢!但是如果每次要等上很多人一起的话,因为说不准什么时候才能够凑够人——所以事实上有可能要等上很久很久才能够进行一次计算,实际上也是很慢的! “那到底要怎么办呢?在等到10分钟,或者凑够一定数量的人两个条件满足一个时就进行运算?”小Ho想出了一个折衷的办法。 “哪有这么麻烦!别忘了和离线算法相对应的可是有一个叫做在线算法的东西呢!”小Hi笑道。 小Ho面临的问题还是和之前一样:假设现在小Ho现在知道了N对父子关系——父亲和儿子的名字,并且这N对父子关系中涉及的所有人都拥有一个共同的祖先(这个祖先出现在这N对父子关系中),他需要对于小Hi的若干次提问——每次提问为两个人的名字(这两个人的名字在之前的父子关系中出现过),告诉小Hi这两个人的所有共同祖先中辈分最低的一个是谁? 提示:最近公共祖先无非就是两点连通路径上高度最小的点嘛! 输入 每个测试点(输入文件)有且仅有一组测试数据。 每组测试数据的第1行为一个整数N,意义如前文所述。 每组测试数据的第2~N+1行,每行分别描述一对父子关系,其中第i+1行为两个由大小写字母组成的字符串Father_i, Son_i,分别表示父亲的名字和儿子的名字。 每组测试数据的第N+2行为一个整数M,表示小Hi总共询问的次数。 每组测试数据的第N+3~N+M+2行,每行分别描述一个询问,其中第N+i+2行为两个由大小写字母组成的字符串Name1_i, Name2_i,分别表示小Hi询问中的两个名字。 对于100%的数据,满足N<=10^5,M<=10^5, 且数据中所有涉及的人物中不存在两个名字相同的人(即姓名唯一的确定了一个人),所有询问中出现过的名字均在之前所描述的N对父子关系中出现过,且每个输入文件中第一个出现的名字所确定的人是其他所有人的公共祖先。 输出 对于每组测试数据,对于每个小Hi的询问,按照在输入中出现的顺序,各输出一行,表示查询的结果:他们的所有共同祖先中辈分最低的一个人的名字。 样例输入 4 Adam Sam Sam Joey Sam Micheal Adam Kevin 3 Sam Sam Adam Sam Micheal Kevin 样例输出 Sam Adam Adam
这应该是最近公共祖先的最后一种算法了吧,hihoCoder还真是循序渐进啊,昨天刚刚学了RMQ-ST算法hihoCoder Problem 1068: RMQ-ST 算法,今天就用上了。 本题的解题思路也是非常的赞,首先把族谱树结构展开成一个数组B,当询问a,b节点的最近公共祖先时,在B中找到a,b最后出现的位置(也就是离开a,b节点的时候)an,bn,在区间[an,bn]上利用RMQ-ST算法求解区间深度最小的节点c,则c即为a,b的最近公共祖先,下面来具体讲解。 将族谱树展开成一个数组 为了利用RMQ-ST算法,需要将树形结构展开成一个数组,展开的方式是深度优先遍历树,将访问的节点顺序记录下来,不管是进入这个节点还是离开这个节点,都需要记录下来。比如下面一棵树:
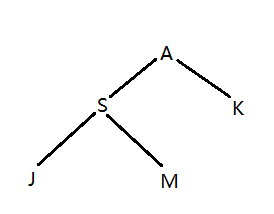 是样例输入构成的一个家谱树,我们常规DFS这个树的序列是这样的:ASJMK。但是本题在进入和离开某个节点时都需要记录下来,而且每访问完一个子节点,要访问下一个子节点时,也需要记录当前父节点。比如访问完J准备访问M时,需要记录S,由此形成的序列为:ASJSMSAKA。
DFS生成的数组B长度大概为边数的两倍,所以复杂度级别只是O(n)的。
DFS之后就把树转换为了数组B[],因为使用RMQ-ST算法需要求某个区间的最小深度节点,所以在DFS的时候还需要记录每个节点的深度信息,而且还要记录每个节点最后访问的下标,这两点都不难,大家直接看代码即可。
RMQ-ST算法
得到数组B后就好办了,可以利用昨天学习的RMQ-ST算法求解2的幂区间长度间深度最小的节点,不过因为我们这题最终输出的是节点的名字而不是节点的深度,所以RMQ-ST比较的是深度,但存储的是节点名。
观察RMQ-ST算法的二重循环知道其复杂度为O(nlgn)。
在线求解
一切准备就绪后就可以求解了,首先根据字符串名字找到对应数字序号,然后查看两节点最后出现在树中的下标l,r,再讲[l,r]区间分成能覆盖[l,r]的2的幂的长度的半区间[l,t]和[t+1,r],最后求这两个区间最小深度的节点,输出其名称。
完整代码如下:
[cpp]
#include<iostream>
#include<map>
#include<string>
#include<vector>
#include<cmath>
using namespace std;
const int MAX_N=100010;//最大人数
map<string,int> name_index;//名字转换为数字
vector<string> index_name(MAX_N);//数字转换为名字
int n,m,k;//k全部记录将树转换成数组tree[]是的下标,转换结束时k即为tree[]的长度
vector<vector<int> > f_s(MAX_N);//f_s[i]表示第i个父亲的所有孩子
int tree[2*MAX_N];//DFS将树转换为的数组
int depth[MAX_N];//每个点在树中的深度
int rmq[MAX_N][30];//区间深度最低值
int last_show[MAX_N];//某个元素最后出现在tree中的位置(下标)
//保存某个人的信息,并返回其下标
int store_name(string name)
{
map<string,int>::iterator it=name_index.find(name);
if(it==name_index.end())//还不存在
{
int curr_index=name_index.size();//用当前已有人数作为其下标,正好是递增的。
name_index.insert(make_pair(name,curr_index));
index_name[curr_index]=name;//记录
return curr_index;//返回下标
}
else
return it->second;//已经存在,直接返回
}
//深度遍历树
void DFS(int root,int deep)
{
tree[k++]=root;//进入即记录
depth[root]=deep;//记录深度
int sons=f_s[root].size();
for(int i=0;i<sons;i++)
{
DFS(f_s[root][i],deep+1);
tree[k++]=root;//每返回一次都要记录一次根节点
}
last_show[root]=k-1;//root节点最后出现的位置
}
//求a,b最小值
inline int get_min(int a,int b)
{
return a<b?a:b;
}
void init_rmq()
{
for(int j=0;j<k;j++)
//rmq[j][0]=depth[tree[j]];
rmq[j][0]=tree[j];//保存的是这个节点,而不是它的深度,方便最后输出
int q=floor(log((double)k)/log(2.0));
for(int i=1;i<=q;i++)
{
for(int j=k-1;j>=0;j–)
{
rmq[j][i]=rmq[j][i-1];
if(j+(1<<(i-1))<k)
{
if(depth[rmq[j+(1<<(i-1))][i-1]]<depth[rmq[j][i]])//+优先级高于<<,所以改j+1<<(i-1)为j+(1<<(i-1))
rmq[j][i]=rmq[j+(1<<(i-1))][i-1];
}
//rmq[j][i]=get_min(rmq[j][i],rmq[j+1<<(i-1)][i-1]);
}
}
}
int main()
{
//freopen("input.txt","r",stdin);
cin>>n;
string name1,name2;
int index1,index2;
while(n–)
{
cin>>name1>>name2;
index1=store_name(name1);
index2=store_name(name2);
f_s[index1].push_back(index2);
}
k=0;//开始时树的下标为0,DFS完之后正好是tree[]数组的长度,可以作为rmq-st的n
DFS(0,0);
init_rmq();
cin>>m;
int l,r,t;
while(m–)
{
cin>>name1>>name2;
if(name1==name2)
{
cout<<name1<<endl;
continue;
}
index1=store_name(name1);
index2=store_name(name2);
l=last_show[index1];
r=last_show[index2];
if(l>r)//保证l<=r
{
int tmp=r;
r=l;
l=tmp;
}
t=floor(log(double(r-l+1))/log(2.0));//找到能使[l,r]分为两半的指数
cout<<index_name[get_min(rmq[l][t],rmq[r-(1<<t)+1][t])]<<endl;//r-(1<<t)+1,记得+1
}
return 0;
}
[/cpp]
本代码提交AC,用时202MS,内存8MB。
相比于hihoCoder Problem 1067: 最近公共祖先·二,本题的的DFS+RMQ-ST算法是在线算法,也就是每来一个询问可以立即回答,而且复杂度为O(nlgn)还不错。
至此,hihoCoder的最近公共祖先问题完整结束,共使用三种算法,后两种算法都利用DFS,阅读时可以互相参照:最近公共祖先问题。
]]>
是样例输入构成的一个家谱树,我们常规DFS这个树的序列是这样的:ASJMK。但是本题在进入和离开某个节点时都需要记录下来,而且每访问完一个子节点,要访问下一个子节点时,也需要记录当前父节点。比如访问完J准备访问M时,需要记录S,由此形成的序列为:ASJSMSAKA。
DFS生成的数组B长度大概为边数的两倍,所以复杂度级别只是O(n)的。
DFS之后就把树转换为了数组B[],因为使用RMQ-ST算法需要求某个区间的最小深度节点,所以在DFS的时候还需要记录每个节点的深度信息,而且还要记录每个节点最后访问的下标,这两点都不难,大家直接看代码即可。
RMQ-ST算法
得到数组B后就好办了,可以利用昨天学习的RMQ-ST算法求解2的幂区间长度间深度最小的节点,不过因为我们这题最终输出的是节点的名字而不是节点的深度,所以RMQ-ST比较的是深度,但存储的是节点名。
观察RMQ-ST算法的二重循环知道其复杂度为O(nlgn)。
在线求解
一切准备就绪后就可以求解了,首先根据字符串名字找到对应数字序号,然后查看两节点最后出现在树中的下标l,r,再讲[l,r]区间分成能覆盖[l,r]的2的幂的长度的半区间[l,t]和[t+1,r],最后求这两个区间最小深度的节点,输出其名称。
完整代码如下:
[cpp]
#include<iostream>
#include<map>
#include<string>
#include<vector>
#include<cmath>
using namespace std;
const int MAX_N=100010;//最大人数
map<string,int> name_index;//名字转换为数字
vector<string> index_name(MAX_N);//数字转换为名字
int n,m,k;//k全部记录将树转换成数组tree[]是的下标,转换结束时k即为tree[]的长度
vector<vector<int> > f_s(MAX_N);//f_s[i]表示第i个父亲的所有孩子
int tree[2*MAX_N];//DFS将树转换为的数组
int depth[MAX_N];//每个点在树中的深度
int rmq[MAX_N][30];//区间深度最低值
int last_show[MAX_N];//某个元素最后出现在tree中的位置(下标)
//保存某个人的信息,并返回其下标
int store_name(string name)
{
map<string,int>::iterator it=name_index.find(name);
if(it==name_index.end())//还不存在
{
int curr_index=name_index.size();//用当前已有人数作为其下标,正好是递增的。
name_index.insert(make_pair(name,curr_index));
index_name[curr_index]=name;//记录
return curr_index;//返回下标
}
else
return it->second;//已经存在,直接返回
}
//深度遍历树
void DFS(int root,int deep)
{
tree[k++]=root;//进入即记录
depth[root]=deep;//记录深度
int sons=f_s[root].size();
for(int i=0;i<sons;i++)
{
DFS(f_s[root][i],deep+1);
tree[k++]=root;//每返回一次都要记录一次根节点
}
last_show[root]=k-1;//root节点最后出现的位置
}
//求a,b最小值
inline int get_min(int a,int b)
{
return a<b?a:b;
}
void init_rmq()
{
for(int j=0;j<k;j++)
//rmq[j][0]=depth[tree[j]];
rmq[j][0]=tree[j];//保存的是这个节点,而不是它的深度,方便最后输出
int q=floor(log((double)k)/log(2.0));
for(int i=1;i<=q;i++)
{
for(int j=k-1;j>=0;j–)
{
rmq[j][i]=rmq[j][i-1];
if(j+(1<<(i-1))<k)
{
if(depth[rmq[j+(1<<(i-1))][i-1]]<depth[rmq[j][i]])//+优先级高于<<,所以改j+1<<(i-1)为j+(1<<(i-1))
rmq[j][i]=rmq[j+(1<<(i-1))][i-1];
}
//rmq[j][i]=get_min(rmq[j][i],rmq[j+1<<(i-1)][i-1]);
}
}
}
int main()
{
//freopen("input.txt","r",stdin);
cin>>n;
string name1,name2;
int index1,index2;
while(n–)
{
cin>>name1>>name2;
index1=store_name(name1);
index2=store_name(name2);
f_s[index1].push_back(index2);
}
k=0;//开始时树的下标为0,DFS完之后正好是tree[]数组的长度,可以作为rmq-st的n
DFS(0,0);
init_rmq();
cin>>m;
int l,r,t;
while(m–)
{
cin>>name1>>name2;
if(name1==name2)
{
cout<<name1<<endl;
continue;
}
index1=store_name(name1);
index2=store_name(name2);
l=last_show[index1];
r=last_show[index2];
if(l>r)//保证l<=r
{
int tmp=r;
r=l;
l=tmp;
}
t=floor(log(double(r-l+1))/log(2.0));//找到能使[l,r]分为两半的指数
cout<<index_name[get_min(rmq[l][t],rmq[r-(1<<t)+1][t])]<<endl;//r-(1<<t)+1,记得+1
}
return 0;
}
[/cpp]
本代码提交AC,用时202MS,内存8MB。
相比于hihoCoder Problem 1067: 最近公共祖先·二,本题的的DFS+RMQ-ST算法是在线算法,也就是每来一个询问可以立即回答,而且复杂度为O(nlgn)还不错。
至此,hihoCoder的最近公共祖先问题完整结束,共使用三种算法,后两种算法都利用DFS,阅读时可以互相参照:最近公共祖先问题。
]]>