39. Combination Sum
Given a set of candidate numbers (candidates) (without duplicates) and a target number (target), find all unique combinations in candidates where the candidate numbers sums to target.
The same repeated number may be chosen from candidates unlimited number of times.
Note:
- All numbers (including
target) will be positive integers. - The solution set must not contain duplicate combinations.
Example 1:
Input: candidates = [2,3,6,7], target = 7,
A solution set is:
[
[7],
[2,2,3]
]
Example 2:
Input: candidates = [2,3,5], target = 8,
A solution set is:
[
[2,2,2,2],
[2,3,3],
[3,5]
]
本题要从一个集合中取出一些数,使得和为某个特定的数target,输出所有的这种组合。注意不能有重复的组合,比如[2,2,3]和[3,2,2]算是重复的。
这是很常见的组合问题,使用递归的思路求解。比如样例,要求和为7,则每个加数必须小于等于7,所以依次尝试2,3,6,7,如果是2,则还差7-2=5,所以递归的在[2,3,6,7]里面找和为5的组合。如此递归,直到差为0。但是这样有一个问题,比如你这一次尝试的是2,则可能得到[2,2,3]的组合,下一次尝试3,则可能得到[3,2,2]的组合,但是这两个组合是相同的。我一开始的想法是对组合排序,然后用set去重。代码如下:
class Solution {
public:
void work(set<vector<int> >& ans, vector<int>& candidates, vector<int>& sol, int target)
{
if (target == 0) {
vector<int> tmp = sol;
sort(tmp.begin(), tmp.end());
ans.insert(tmp);
}
else {
for (int i = 0; i < candidates.size(); i++) {
if (candidates[i] > target)
break;
sol.push_back(candidates[i]);
work(ans, candidates, sol, target – candidates[i]);
sol.pop_back();
}
}
}
vector<vector<int> > combinationSum(vector<int>& candidates, int target)
{
set<vector<int> > ans;
vector<int> sol;
sort(candidates.begin(), candidates.end());
work(ans, candidates, sol, target);
return vector<vector<int> >(ans.begin(), ans.end());
}
};
本代码提交AC,但是用时145MS,只击败了4.5%的人,所以肯定还有更优的方案。
上述方案的一个费时的地方就是要对每个组合排序,然后用set去重,如果能省掉这个环节,速度会快很多。
网上查看题解之后,恍然大悟,每次只选不小于上一次选过的数,这样得到的组合就不会有重复,不需要排序,也不需要set去重。比如上面的例子,在选到3时,差7-3=4,此时再从[2,3,6,7]里面选时,只选大于等于3的数,也就是3,6,7,不再考虑2了。但是6,7都大于4,不行;3的话,剩余4-3=1也无解。所以搜3的时候,就不会得到[3,2,2]的结果,也就无需去重。
完整代码如下:
class Solution {
public:
void work(vector<vector<int> >& ans, vector<int>& candidates, vector<int>& sol, int target)
{
if (target == 0) {
ans.push_back(sol);
}
else {
for (int i = 0; i < candidates.size(); i++) {
if (candidates[i] > target || (sol.size() > 0 && candidates[i] < sol[sol.size() – 1]))
continue;
sol.push_back(candidates[i]);
work(ans, candidates, sol, target – candidates[i]);
sol.pop_back();
}
}
}
vector<vector<int> > combinationSum(vector<int>& candidates, int target)
{
vector<vector<int> > ans;
vector<int> sol;
sort(candidates.begin(), candidates.end());
work(ans, candidates, sol, target);
return ans;
}
};
本代码提交AC,用时20MS,速度快了好多。
后来我发现这个版本的代码还可以优化,因为candidates已经排好序了,如果这次取了i号元素,下一次只要取i及以后的元素即可,所以在递归的时候多传入一个下标值,也能提速。完整代码如下:
class Solution {
public:
void work(vector<vector<int> >& ans, vector<int>& candidates, int idx, vector<int>& sol, int target)
{
if (target == 0) {
ans.push_back(sol);
}
else {
for (int i = idx; i < candidates.size(); i++) {
if (candidates[i] > target)
break;
sol.push_back(candidates[i]);
work(ans, candidates, i, sol, target – candidates[i]);
sol.pop_back();
}
}
}
vector<vector<int> > combinationSum(vector<int>& candidates, int target)
{
vector<vector<int> > ans;
vector<int> sol;
sort(candidates.begin(), candidates.end());
work(ans, candidates, 0, sol, target);
return ans;
}
};
本代码提交AC,用时16MS。
二刷。没必要排序,直接DFS选当前及后续元素即可,代码如下:
class Solution {
public:
void dfs(vector<int>& candidates, int target, vector<vector<int>>& ans, vector<int>& cur, int idx) {
if (target == 0) {
ans.push_back(cur);
return;
}
if (target < 0)return;
for (int i = idx; i < candidates.size(); ++i) {
target -= candidates[i];
cur.push_back(candidates[i]);
dfs(candidates, target, ans, cur, i);
cur.pop_back();
target += candidates[i];
}
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
vector<vector<int>> ans;
vector<int> cur;
dfs(candidates, target, ans, cur, 0);
return ans;
}
};
本代码提交AC,用时12MS。

 每两个点之间至少有一条路径连通,当切断边(3,4)的时候,可以发现,整个网络被隔离为{1,2,3},{4,5,6}两个部分:
每两个点之间至少有一条路径连通,当切断边(3,4)的时候,可以发现,整个网络被隔离为{1,2,3},{4,5,6}两个部分:
 若关闭服务器3,则整个网络被隔离为{1,2},{4,5,6}两个部分:
若关闭服务器3,则整个网络被隔离为{1,2},{4,5,6}两个部分:
 小Hi和小Ho想要知道,在学校的网络中有哪些连接和哪些点被关闭后,能够使得整个网络被隔离为两个部分。
在上面的例子中,满足条件的有边(3,4),点3和点4。
提示:割边&割点
输入
第1行:2个正整数,N,M。表示点的数量N,边的数量M。1≤N≤20,000, 1≤M≤100,000
第2..M+1行:2个正整数,u,v。表示存在一条边(u,v),连接了u,v两台服务器。1≤u<v≤N
保证输入所有点之间至少有一条连通路径。
输出
第1行:若干整数,用空格隔开,表示满足要求的服务器编号。从小到大排列。若没有满足要求的点,该行输出Null
第2..k行:每行2个整数,(u,v)表示满足要求的边,u<v。所有边根据u的大小排序,u小的排在前,当u相同时,v小的排在前面。若没有满足要求的边,则不输出
样例输入
6 7
1 2
1 3
2 3
3 4
4 5
4 6
5 6
样例输出
3 4
3 4
小Hi和小Ho想要知道,在学校的网络中有哪些连接和哪些点被关闭后,能够使得整个网络被隔离为两个部分。
在上面的例子中,满足条件的有边(3,4),点3和点4。
提示:割边&割点
输入
第1行:2个正整数,N,M。表示点的数量N,边的数量M。1≤N≤20,000, 1≤M≤100,000
第2..M+1行:2个正整数,u,v。表示存在一条边(u,v),连接了u,v两台服务器。1≤u<v≤N
保证输入所有点之间至少有一条连通路径。
输出
第1行:若干整数,用空格隔开,表示满足要求的服务器编号。从小到大排列。若没有满足要求的点,该行输出Null
第2..k行:每行2个整数,(u,v)表示满足要求的边,u<v。所有边根据u的大小排序,u小的排在前,当u相同时,v小的排在前面。若没有满足要求的边,则不输出
样例输入
6 7
1 2
1 3
2 3
3 4
4 5
4 6
5 6
样例输出
3 4
3 4
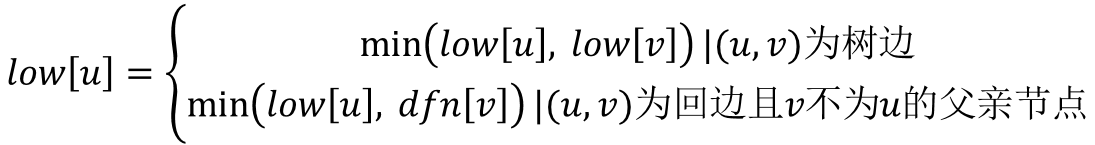 主要要理解上面的递推公式。首先理解dfn和low的含义,dfn[u]记录节点u在DFS过程中被遍历到的次序号,low[u]记录节点u或u的子树通过非父子边追溯到最早的祖先节点(即DFS次序号最小)。
上图的第一个式子,当(u,v)为树边时,low[u]表明u能追溯到的最早节点,low[v]表明u的子树(v就是u的子树的根)能追溯到的最早节点,所以根据low[u]的定义有low[u]=min(low[u],low[v])。
上图的第二个式子,当(u,v)为回边时,因为low[u]的定义就是u通过非父子边(回边)追溯最早的节点,所以既然(u,v)为回边,自然的low[u]=min(low[u],dfn[v])。
另外注意输出格式,点要从小到大排列;边(u,v)保证u<v,以u从小到大排列,再以v从小到大排列。完整代码如下:
[cpp]
#include<iostream>
#include<cstdio>
#include<set>
#include<algorithm>
#include<vector>
using namespace std;
const int kMaxN = 20005;
int n, m;
typedef struct edge
{
int x, y;
bool operator<(const edge& p)const//如果要加入到set中,需要重载<
{
return (this->x<p.x) || ((this->x == p.x) && (this->y<p.y));
}
};
set<int> points;
set<edge> edges;
vector<vector<int>> graph;
int visit[kMaxN];
int dfn[kMaxN];
int low[kMaxN];
int parent[kMaxN];
void dfs(int u) {
//记录dfs遍历次序
static int counter = 0;
//记录节点u的子树数
int children = 0;
visit[u] = 1;
//初始化dfn与low
dfn[u] = low[u] = ++counter;
for (int i = 0; i < graph[u].size();i++) {
int v = graph[u][i];
//节点v未被访问,则(u,v)为树边
if (visit[v]==0) {
children++;
parent[v] = u;
dfs(v);
low[u] = min(low[u], low[v]);
//case (1)
if (parent[u] == 0 && children > 1) {
points.insert(u);
}
//case (2)
if (parent[u] != 0 && low[v] >= dfn[u]) {
points.insert(u);
}
//bridge
if (low[v] > dfn[u]) {
edge e;
e.x = u;
e.y = v;
if (u > v)
{
e.x = v;
e.y = u;
}
edges.insert(e);
}
}
//节点v已访问,则(u,v)为回边
else if (v != parent[u]) {
low[u] = min(low[u], dfn[v]);
}
}
}
int main()
{
scanf("%d %d", &n, &m);
graph.resize(n + 1);
int u, v;
while (m–)
{
scanf("%d %d", &u, &v);
graph[u].push_back(v);
graph[v].push_back(u);
}
dfs(1);
if (points.size() == 0)
printf("Null\n");
else
{
set<int>::iterator it = points.begin();
while (it != points.end())
{
printf("%d ", *it);
it++;
}
printf("\n");
}
if (edges.size() > 0)
{
set<edge>::iterator it = edges.begin();
while (it != edges.end())
{
printf("%d %d\n", (*it).x, (*it).y);
it++;
}
}
return 0;
}
[/cpp]
本代码提交AC,用时76MS,内存7MB。]]>
主要要理解上面的递推公式。首先理解dfn和low的含义,dfn[u]记录节点u在DFS过程中被遍历到的次序号,low[u]记录节点u或u的子树通过非父子边追溯到最早的祖先节点(即DFS次序号最小)。
上图的第一个式子,当(u,v)为树边时,low[u]表明u能追溯到的最早节点,low[v]表明u的子树(v就是u的子树的根)能追溯到的最早节点,所以根据low[u]的定义有low[u]=min(low[u],low[v])。
上图的第二个式子,当(u,v)为回边时,因为low[u]的定义就是u通过非父子边(回边)追溯最早的节点,所以既然(u,v)为回边,自然的low[u]=min(low[u],dfn[v])。
另外注意输出格式,点要从小到大排列;边(u,v)保证u<v,以u从小到大排列,再以v从小到大排列。完整代码如下:
[cpp]
#include<iostream>
#include<cstdio>
#include<set>
#include<algorithm>
#include<vector>
using namespace std;
const int kMaxN = 20005;
int n, m;
typedef struct edge
{
int x, y;
bool operator<(const edge& p)const//如果要加入到set中,需要重载<
{
return (this->x<p.x) || ((this->x == p.x) && (this->y<p.y));
}
};
set<int> points;
set<edge> edges;
vector<vector<int>> graph;
int visit[kMaxN];
int dfn[kMaxN];
int low[kMaxN];
int parent[kMaxN];
void dfs(int u) {
//记录dfs遍历次序
static int counter = 0;
//记录节点u的子树数
int children = 0;
visit[u] = 1;
//初始化dfn与low
dfn[u] = low[u] = ++counter;
for (int i = 0; i < graph[u].size();i++) {
int v = graph[u][i];
//节点v未被访问,则(u,v)为树边
if (visit[v]==0) {
children++;
parent[v] = u;
dfs(v);
low[u] = min(low[u], low[v]);
//case (1)
if (parent[u] == 0 && children > 1) {
points.insert(u);
}
//case (2)
if (parent[u] != 0 && low[v] >= dfn[u]) {
points.insert(u);
}
//bridge
if (low[v] > dfn[u]) {
edge e;
e.x = u;
e.y = v;
if (u > v)
{
e.x = v;
e.y = u;
}
edges.insert(e);
}
}
//节点v已访问,则(u,v)为回边
else if (v != parent[u]) {
low[u] = min(low[u], dfn[v]);
}
}
}
int main()
{
scanf("%d %d", &n, &m);
graph.resize(n + 1);
int u, v;
while (m–)
{
scanf("%d %d", &u, &v);
graph[u].push_back(v);
graph[v].push_back(u);
}
dfs(1);
if (points.size() == 0)
printf("Null\n");
else
{
set<int>::iterator it = points.begin();
while (it != points.end())
{
printf("%d ", *it);
it++;
}
printf("\n");
}
if (edges.size() > 0)
{
set<edge>::iterator it = edges.begin();
while (it != edges.end())
{
printf("%d %d\n", (*it).x, (*it).y);
it++;
}
}
return 0;
}
[/cpp]
本代码提交AC,用时76MS,内存7MB。]]>